«统计学完全教程»笔记:第9章 参数推断
考虑参数化模型,
$$ \mathfrak{F}=\{f(x ; \theta): \theta \in \Theta\} $$其中 $ \Theta \subset \mathbb{R}^{k} $ 是参数的空间, $ \theta=\left(\theta_{1}, \ldots, \theta_{k}\right) $ 是参数。
参数推理的问题就归结为估计参数 $ \theta $ 的问题。
常见的问题:如何确定生成数据的分布是哪种参数化模型呢 ? 难! 参数 化模型的优势:
-
有先验知识可以知道数据近似服从某种参数化模型。如,交通事故发 生的次数近似服从泊松分布。
-
参数化模型的推断为理解非参数方法提供了背景知识。 这样, 我们还是要学习参数化模型。
关注参数
人们通常只关注某个函数 $ T(\theta) $ 。例如,如果 $ X \sim N\left(\mu, \sigma^{2}\right) $ 的分布,那么 参数为 $ \theta=(\mu, \sigma) $ 。如果我们的目标是估计 $ \mu $ ,那么 $ \mu=T(\theta) $ 为关注参数(parameter of interest), $ \sigma $ 为冗余参数 (nuisance parameter)。
例题 令 $ X_{1}, \ldots, X_{n} \sim \operatorname{Normal}\left(\mu, \sigma^{2}\right) $ 。参数 $ \theta=(\mu, \sigma) $, 参数空间为 $ \Theta=\{(\mu, \sigma): \mu \in \mathbb{R}, \sigma>0\} $ 。假设 $ X_{i} $ 是血液检测的输出, 我们对于参数 $ \tau $ 感兴趣,也就是测试评分超过 1 的人数的比例。令 $ Z $ 表示标准正态分 布随机变量,那么,
$$ \begin{aligned} \tau &=\mathbb{P}(X>1)=1-\mathbb{P}(X<1)=1-\mathbb{P}\left(\dfrac{X-\mu}{\sigma}<\dfrac{1-\mu}{\sigma}\right) \\ &=1-\mathbb{P}\left(Z<\dfrac{1-\mu}{\sigma}\right)=1-\Phi\left(\dfrac{1-\mu}{\sigma}\right) \end{aligned} $$感兴趣参数是 $ \tau=T(\mu, \sigma)=1-\Phi((1-\mu) / \sigma) $ 。
例题 如果 $ X $ 服从 $ \operatorname{Gamma}(\alpha, \beta) $ 的分布, 如果满足
$$ f(x ; \alpha, \beta)=\dfrac{1}{\beta^{\alpha} \Gamma(\alpha)} x^{\alpha-1} e^{-x / \beta}, \quad x>0 $$其中, $ \alpha, \beta>0 $ 并且
$$ \Gamma(\alpha)=\int_{0}^{\infty} y^{\alpha-1} e^{-y} d y $$为 Gamma 函数。参数是 $ \theta=(\alpha, \beta) $ 。Gamma 分布有时用于建模人、动 物、或者电子设备的寿命。假定我们估计平均寿命, 则
$$ T(\alpha, \beta)=\mathbb{E}_{\theta}\left(X_{1}\right)=\alpha \beta $$矩估计
-
第一种用于参数估计的方法称为矩方法。我们将会看到,这些估计 器的并不是最优的, 但是他们却容易计算。这些方法得到的结果对 于需要迭代数值计算的方法是很好的初始值。
-
假定我们有参数 $ \theta=\left(\theta_{1}, \ldots, \theta_{k}\right) $ 包括 $ k $ 个成分。对于 $ 1 \leq j \leq k $, 定义 $j$ 阶矩 (Moment) 为
- 同时, 定义第 $ j $ 阶样本矩 (Sample Moment) 为
定义 矩估计器 $ \hat{\theta}_{n} $ 定义为满足
$$ \begin{array}{c} \alpha_{1}\left(\widehat{\theta}_{n}\right)=\widehat{\alpha}_{1} \\ \alpha_{2}\left(\widehat{\theta}_{n}\right)=\widehat{\alpha}_{2} \\ :: \\ \alpha_{k}\left(\widehat{\theta}_{n}\right)=\widehat{\alpha}_{k} \end{array} $$的 $ \theta $ 值。以上公式定义了关于 $ k $ 个末知数的 $ k $ 个方程。
总体的各阶中心矩的矩估计就是样本各阶中心矩。
例题 假设 $ X_{1}, \ldots, X_{n} \sim \operatorname{Bernoulli}(p) $ 。那么 $ \alpha_{1}=\mathbb{E}_{p}(X)=p $ 并且 $ \widehat{\alpha}_{1}=n^{-1} \sum_{i=1}^{n} X_{i} $ 。令他们相等, 得到
$$ \widehat{p}_{n}=\dfrac{1}{n} \sum_{i=1}^{n} X_{i} $$矩估计定理
假设 $ \widehat{\theta}_{n} $ 表示矩估计器。在关于模型正确的条件下, 下面的陈述成立:
-
估计器 $ \hat{\theta}_{n} $ 存在的概率趋近于 1 。
-
这个估计器是一致估计, 即 $ \widehat{\theta}_{n} \stackrel{\mathrm{P}}{\longrightarrow} \theta $ 。
-
这个估计是渐进正态的,即
其中
$$ \Sigma=g \mathbb{E}_{\theta}\left(Y Y^{T}\right) g^{T} $$并且,
$$ Y=\left(X, X^{2}, \ldots, X^{k}\right)^{T}, g=\left(g_{1}, \ldots, g_{k}\right), g_{j}=\partial \alpha_{j}^{-1}(\theta) / \partial \theta $$定理中的第三个陈述可以用于寻找标准误差和置信区间。但是,可以采 用更为简单的 Bootstrap 方式。
极大似然估计
参数化模型中最为常用的估计参数的方法是极大似然估计法。假定 $ X_{1}, \ldots, X_{n} $ 是独立同分布具有概率密度函数为 $ f(x ; \theta) $ 。 似然函数定义为
$$ \mathcal{L}_{n}(\theta)=\prod_{i=1}^{n} f\left(X_{i} ; \theta\right) $$对数似然函数定义为 $ \ell_{n}(\theta)=\log \mathcal{L}_{n}(\theta) $ 。 似然函数仅仅是数据的联合密度函数,只是把它看作是关于参数 $ \theta $ 的函 数。这样, $ \mathcal{L}_{n}: \Theta \rightarrow[0, \infty) $ 。似然函数并不是密度函数。一般而言,并 不能保证似然函数 $ \mathcal{L}_{n}(\theta) $ 关于 $ \theta $ 的积分为 1 。
定义: 极大似然估计器 (MLE), 表示为 $ \widehat{\theta}_{n} $ 是使得似然函数最大的 $ \theta $ 的 值。 对数似然函数和似然函数在同一点取得最大值。因此, 最大化对数似然 函数产生最大化似然函数相同的结果。但通常我们最大化对数似然函数 更为简单。 注释: 如果在似然函数 $ \mathcal{L}_{n}(\theta) $ 上乘以正常数 $ c $ (与 $ \theta $ 无关),这不会改变 极大似然估计器的结果。因此,我们通常要丟弃似然函数中的正常数。
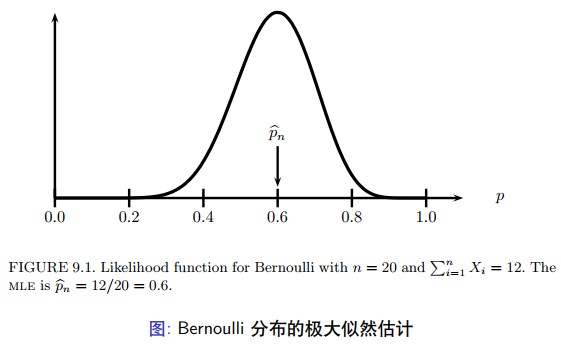
假定 $ X_{1}, \ldots, X_{n} \sim $ Bernoulli $ (p) $ 。概率函数 $ f(x ; p)=p^{x}(1-p)^{1-x} $ 对于 $ x=0,1 $ 。其中 $ p $ 为末知参数。那么,
$$ \mathcal{L}_{n}(p)=\prod_{i=1}^{n} f\left(X_{i} ; p\right)=\prod_{i=1}^{n} p^{X_{i}}(1-p)^{1-X_{i}}=p^{S}(1-p)^{n-S} $$其中, $ S=\sum_{i} X_{i} $ 。因此,
$$ \ell_{n}(p)=S \log p+(n-S) \log (1-p) $$对对数似然函数求导数,设其为 0 ,就可以得到 MLE 的结果 $ \widehat{p}_{n}=S / n $ 。 如图。
假设随机变量 $ X_{1}, \ldots, X_{n} \sim N\left(\mu, \sigma^{2}\right) $ 。参数 $ \theta=(\mu, \sigma) $, 并且似然函数 (忽略常数项) 是:
$$ \begin{aligned} \mathcal{L}_{n}(\mu, \sigma) &=\prod_{i} \dfrac{1}{\sigma} \exp \left\{-\dfrac{1}{2 \sigma^{2}}\left(X_{i}-\mu\right)^{2}\right\} \\ &=\sigma^{-n} \exp \left\{-\dfrac{1}{2 \sigma^{2}} \sum_{i}\left(X_{i}-\mu\right)^{2}\right\} \\ &=\sigma^{-n} \exp \left\{-\dfrac{n S^{2}}{2 \sigma^{2}}\right\} \exp \left\{-\dfrac{n(\bar{X}-\mu)^{2}}{2 \sigma^{2}}\right\} \end{aligned} $$其中 $ \bar{X}=n^{-1} \sum_{i} X_{i} $ 为样本均值,样本方差 $ S^{2}=n^{-1} \sum_{i}\left(X_{i}-\bar{X}\right)^{2} $ 。 上式中,利用 $ \sum_{i}\left(X_{i}-\mu\right)^{2}=n S^{2}+n(\bar{X}-\mu)^{2} $ ,可以通过 $ \sum_{i}\left(X_{i}-\mu\right)^{2}=\sum_{i}\left(X_{i}-\bar{X}+\bar{X}-\mu\right)^{2} $ , 随后将平方项展开。
对数似然函数为
$$ \ell(\mu, \sigma)=-n \log \sigma-\dfrac{n S^{2}}{2 \sigma^{2}}-\dfrac{n(\bar{X}-\mu)^{2}}{2 \sigma^{2}} $$求解方程
$$ \dfrac{\partial \ell(\mu, \sigma)}{\partial \mu}=0 \quad \text { and } \quad \dfrac{\partial \ell(\mu, \sigma)}{\partial \sigma}=0 $$可以得到, $ \hat{\mu}=\bar{X}, \widehat{\sigma}=S $ 。可以证明他们是全局极大似然值。
再例
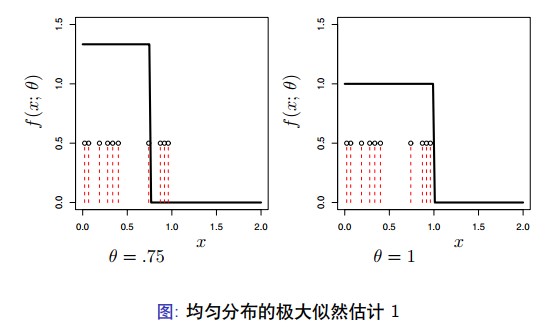
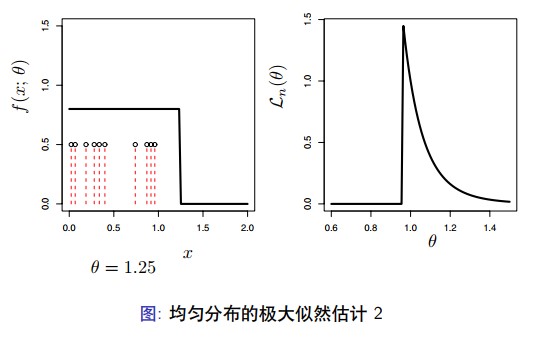
假定 $ X_{1}, \ldots, X_{n} \sim U n i f(0, \theta) $ 。这样, 概率密度函数
$$ f(x ; \theta)=\left\{\begin{array}{lr} 1 / \theta & 0 \leq x \leq \theta \\ 0 & \text { otherwise } \end{array}\right. $$ 考虑 $ \theta $ 一个固定的值,假设 $ \theta 再考虑 $ \theta \geq X_{(n)} $ 。对于每个 $ X_{i} $, 那么我们有 $ f\left(X_{i} ; \theta\right)=1 / \theta $, 这样 $ \mathcal{L}_{n}(\theta)=\prod_{i} f\left(X_{i} ; \theta\right)=\theta^{-n} $ 。总之,
极大似然估计的性质
-
一致性
-
等变性
-
渐近正态性
-
最优性
在某些条件下, 极大似然估计器具有良好的性质, 这也是它具有吸引力 的原因。这些性质包括:
-
极大似然估计是一致估计 (consistent), $ \widehat{\theta}_{n} \longrightarrow{P}{\longrightarrow} \theta_{\star} $, 其中 $ \theta_{*} $ 表示参数 的真实值。
-
极大似然估计是同变估计 (equivariant), 如果 $ \widehat{\theta}_{n} $ 是 $ \theta $ 极大似然估计, 则 $ g\left(\widehat{\theta}_{n}\right) $ 就是 $ g(\theta) $ 的极大似然估计。
-
极大似然估计是渐进状态 (asympotically Normal) 的, $ \left(\hat{\theta}-\theta_{\star}\right) / \widehat{\mathrm{se}} \rightsquigarrow N(0,1) $, 同样, 估计的标准差 $ \widehat{S e} $ 可以分析求解得到。
-
极大似然估计是渐进最优的、有效的。这意味着,在所有表现正常的 估计器中, 极大似然估计的方差最小, 至少在大样本情形下成立。
-
极大似然估计是渐进的 Bayes 估计器。 注意: 并不是 MLE 总是最好的, 在一般情形下, 是最好的。如果模型 满足某些正则条件 (regularity conditions)。这些是函数 $ f(x ; \theta) $ 满足平滑 性 (smoothness) 的基本条件。
一致性意味着 MLE 依概率收敛至真实值。 如果 $ f $ 和 $ g $ 是概率密度函数。定义两个密度函数之间的 $ \mathrm{KL} $ 距离为,
$$ D(f, g)=\int f(x) \log \left(\dfrac{f(x)}{g(x)}\right) d x $$对于任意的参数 $ \theta, \psi \in \Theta $ ,如果记 $ D(\theta, \psi) $ ,就意味着 $ D(f(x ; \theta), f(x ; \psi)) $ 。 我们定义模型 $ \mathfrak{F} $ 是可以辨识的 (Indentifiable), 如果 $ \theta \neq \psi $, 意味着 $ D(\theta, \psi)>0 $ 。也就是,不同的参数值对应于不同的分布函数。现在,假 定模型是可辨识的。
假定 $ \theta_{*} $ 表示参数 $ \theta $ 的真实值。最大化对数似然函数 $ \ell_{n}(\theta) $, 等价于最大 化
$$ M_{n}(\theta)=\dfrac{1}{n} \sum_{i} \log \dfrac{f\left(X_{i} ; \theta\right)}{f\left(X_{i} ; \theta_{\star}\right)} $$由于 $ M_{n}(\theta)=n^{-1}\left(\ell_{n}(\theta)-\ell_{n}\left(\theta_{\star}\right)\right) $ ,并且 $ \ell_{n}\left(\theta_{\star}\right) $ 是常数(关于 $ \theta $ )。由大 数定律, $ M_{n}(\theta) $ 将收敛于
$$ \begin{aligned} \mathbb{E}_{\theta_{\star}}\left(\log \dfrac{f\left(X_{i} ; \theta\right)}{f\left(X_{i} ; \theta_{\star}\right)}\right) &=\int \log \left(\dfrac{f(x ; \theta)}{f\left(x ; \theta_{\star}\right)}\right) f\left(x ; \theta_{\star}\right) d x \\ &=-\int \log \left(\dfrac{f\left(x ; \theta_{\star}\right)}{f(x ; \theta)}\right) f\left(x ; \theta_{\star}\right) d x \\ &=-D\left(\theta_{\star}, \theta\right) \end{aligned} $$因此, $ M_{n}(\theta) \approx-D\left(\theta_{\star}, \theta\right) $, 在 $ \theta_{\star} $ 时取得最大值。考虑 $ \mathrm{KL} $ 的非负性。 因此, 我们期望最大化参数趋近于 $ \theta_{\star} $ 。我们需要证明这个收敛是一致 的。同时,还需要证明这个函数 $ D\left(\theta_{\star}, \theta\right) $ 是良性的。
$ 9.13 $ 定理 假定 $ \theta_{*} $ 表示参数 $ \theta $ 的真实值。定义
$$ M_{n}(\theta)=\dfrac{1}{n} \sum_{i} \log \dfrac{f\left(X_{i} ; \theta\right)}{f\left(X_{i} ; \theta_{\star}\right)} $$并且, $ M(\theta)=-D\left(\theta_{\star}, \theta\right) $ 。假设
$$ \sup _{\theta \in \Theta}\left|M_{n}(\theta)-M(\theta)\right| \stackrel{\mathrm{P}}{\longrightarrow} 0 $$对于任意 $ \epsilon>0 $,
$$ \sup _{\theta:\left|\theta-\theta_{\star}\right| \geq \epsilon} M(\theta)$ 9.14 $ 定理 假定 $ \tau=g(\theta) $ 是关于 $ \theta $ 的函数。假定 $ \widehat{\theta}_{n} $ 是参数 $ \theta $ 的极大似然估计。那 么, $ \widehat{\tau}_{n}=g\left(\widehat{\theta}_{n}\right) $ 就是 $ \tau $ 的极大似然估计。 证明: 假定 $ h=g^{-1} $ 表示 $ g $ 的反函数。那么, $ \widehat{\theta}_{n}=h\left(\widehat{\tau}_{n}\right) $ ,对于任意 $ \tau $ , 似然函数 $ \mathcal{L}(\tau)=\prod_{i} f\left(x_{i} ; h(\tau)\right)=\prod_{i} f\left(x_{i} ; \theta\right)=\mathcal{L}(\theta) $ , 其中 $ \theta=h(\tau) $ 。因 此,对于任意 $ \tau , \mathcal{L}_{n}(\tau)=\mathcal{L}(\theta) \leq \mathcal{L}(\widehat{\theta})=\mathcal{L}_{n}(\widehat{\tau}) $ 。
$ 9.15 $ 例题 假设 $ X_{1}, \ldots, X_{n} \sim N(\theta, 1) $ ,对于参数 $ \theta $ 的极大似然估计 $ \widehat{\theta}_{n}=\bar{X}_{n} $ 。假定 $ \tau=e^{\theta} $ ,那么,参数 $ \tau $ 的极大似然估计 $ \widehat{\tau}=e^{\widehat{\theta}}=e^{\bar{x}} $ 。
$ 9.16 $ 定义 评分函数定义如下,
$$ s(X ; \theta)=\dfrac{\partial \log f(X ; \theta)}{\partial \theta} $$Fisher 信息量定义为
$$ \begin{aligned} I_{n}(\theta) &=\mathbb{V}_{\theta}\left(\sum_{i=1}^{n} s\left(X_{i} ; \theta\right)\right) \\ &=\sum_{i=1}^{n} \mathbb{V}_{\theta}\left(s\left(X_{i} ; \theta\right)\right) \end{aligned} $$对于 $ n=1 $ 时,我们更倾向于记为 $ I(\theta) $, 而不是 $ I_{1}(\theta) $ 。可以证明, $ \mathbb{E}_{\theta}(s(X ; \theta))=0 $ 。这样,我们可以得到, $ \mathbb{V}_{\theta}(s(X ; \theta))=\mathbb{E}_{\theta}\left(s^{2}(X ; \theta)\right) $ 。事 实上, 我们可以进一步简化 $ I_{n}(\theta) $ 。
$ 9.17 $ 定理 $ I_{n}(\theta)=n I(\theta) $, 同时
$$ \begin{aligned} I(\theta) &=-\mathbb{E}_{\theta}\left(\dfrac{\partial^{2} \log f(X ; \theta)}{\partial \theta^{2}}\right) \\ &=-\int\left(\dfrac{\partial^{2} \log f(x ; \theta)}{\partial \theta^{2}}\right) f(x ; \theta) d x \end{aligned} $$$ 9.18 $ 定理 (极大似然估计的渐进正态性) 假设 se $ =\sqrt{\mathbb{V}\left(\widehat{\theta}_{n}\right)} $ ,在适当的正则条件下,有下列等式成立:
- se $ \approx \sqrt{1 / I_{n}(\theta)} $, 且
- 令 $ \widehat{\mathrm{se}}=\sqrt{1 / I_{n}\left(\widehat{\theta}_{n}\right)} $, 则
第一个陈述表明, $ \widehat{\theta}_{n} \approx N(\theta, \mathrm{se}) $, 其中 $ \widehat{\theta}_{n} $ 的渐进标准差为 se $ =\sqrt{1 / I_{n}(\theta)} $ 。 第二个陈述表明,即便我们用估计标准差 $ \widehat{\mathrm{e}}=\sqrt{1 / I_{n}\left(\widehat{\theta}_{n}\right)} $ 替代标准差, 第一个陈述依然成立。 这样, 我们就可以说明极大似然估计的分布可以用 $ N\left(\theta, \widehat{\mathrm{se}}^{2}\right) $ 渐进估计。 基于以上事实,我们可以构建一个渐进的置信区间。
$ 9.19 $ 定理 令
$$ C_{n}=\left(\widehat{\theta}_{n}-z_{\alpha / 2} \widehat{\mathrm{se}}, \widehat{\theta}_{n}+z_{\alpha / 2} \widehat{\mathrm{se}}\right) $$那么, $ \mathbb{P}_{\theta}\left(\theta \in C_{n}\right) \rightarrow 1-\alpha $ ,当 $ n \rightarrow \infty $ 。 证明: 假定 $ Z $ 表示服从标准正态分布的随机变量。那么,
$$ \begin{aligned} \mathbb{P}_{\theta}\left(\theta \in C_{n}\right) &=\mathbb{P}_{\theta}\left(\widehat{\theta}_{n}-z_{\alpha / 2} \widehat{\mathrm{e}} \leq \theta \leq \widehat{\theta}_{n}+z_{\alpha / 2} \widehat{\mathrm{se}}\right) \\ &=\mathbb{P}_{\theta}\left(-z_{\alpha / 2} \leq \dfrac{\widehat{\theta}_{n}-\theta}{\widehat{\mathrm{se}}} \leq z_{\alpha / 2}\right) \\ & \rightarrow \mathbb{P}\left(-z_{\alpha / 2}是渐进的 $ 95 \% $ 的置信区间。
$ 9.20 $ 例题 假定 $ X_{1}, \ldots, X_{n} \sim $ Bernoulli $ (p) $ 。极大似然估计是 $ \widehat{p}_{n}=\sum_{i} X_{i} / n $, 并且, $ f(x ; p)=p^{x}(1-p)^{1-x} $, $ \log f(x ; p)=x \log p+(1-x) \log (1-p) $,
$$ s(X ; p)=\dfrac{X}{p}-\dfrac{1-X}{1-p} $$并且,
$$ -s^{\prime}(X ; p)=\dfrac{X}{p^{2}}+\dfrac{1-X}{(1-p)^{2}} $$这样,
$$ I(p)=\mathbb{E}_{p}\left(-s^{\prime}(X ; p)\right)=\dfrac{p}{p^{2}}+\dfrac{(1-p)}{(1-p)^{2}}=\dfrac{1}{p(1-p)} $$因此,
$$ \widehat{\mathrm{se}}=\dfrac{1}{\sqrt{I_{n}\left(\widehat{p}_{n}\right)}}=\dfrac{1}{\sqrt{n l\left(\hat{p}_{n}\right)}}=\left\{\dfrac{\widehat{p}(1-\widehat{p})}{n}\right\}^{1 / 2} $$一个 $ 95 \% $ 的渐进置信区间为
$$ \widehat{p}_{n} \pm 2\left\{\dfrac{\widehat{p}_{n}\left(1-\widehat{p}_{n}\right)}{n}\right\}^{1 / 2} $$$ 9.21 $ 例题 令 $ X_{1}, \ldots, X_{n} \sim N\left(\theta, \sigma^{2}\right) $, 其中 $ \sigma^{2} $ 已知。评分函数 $ s(X ; \theta)=(X-\theta) / \sigma^{2} $ 并且 $ s^{\prime}(X ; \theta)=-1 / \sigma^{2} $ ,因此 $ I_{1}(\theta)=1 / \sigma^{2} $ 。极大似 然估计是 $ \widehat{\theta}_{n}=\bar{X}_{n} $ 。根据 $ 9.18 $ 定理, $ \bar{X}_{n} \approx N\left(\theta, \sigma^{2} / n\right) $ 。这种情况下,正 态渐进就是完全精确的。
$ 9.22 $ 例题 假定 $ X_{1}, \ldots, X_{n} \sim $ Poisson $ (\lambda) $ 。那么, $ \widehat{\lambda}_{n}=\bar{X}_{n} $ 。计算可以得到 $ I_{1}(\lambda)=1 / \lambda $, 因此,
$$ \widehat{\mathrm{se}}=\dfrac{1}{\sqrt{n l}\left(\widehat{\lambda}_{n}\right)}=\sqrt{\dfrac{\widehat{\lambda}_{n}}{n}} $$因此, $ \lambda $ 的 $ 1-\alpha $ 渐进置信区间为 $ \widehat{\lambda}_{n} \pm z_{\alpha / 2} \sqrt{\hat{\lambda}_{n} / n} $ 。
假设 $ X_{1}, \ldots, X_{n} \sim N\left(\theta, \sigma^{2}\right) $ 。极大似然估计是 $ \widehat{\theta}_{n}=\bar{X}_{n} $ 。另一个合理的 参数 $ \theta $ 的估计是样本中值 $ \widetilde{\theta}_{n} $ 。极大似然估计满足
$$ \sqrt{n}\left(\widehat{\theta}_{n}-\theta\right) \leadsto N\left(0, \sigma^{2}\right) $$中值估计满足
$$ \sqrt{n}\left(\widetilde{\theta}_{n}-\theta\right) \rightsquigarrow N\left(0, \sigma^{2} \dfrac{\pi}{2}\right) $$这表明,中值估计收敛于正确的值,但是它的方差比极大似然估计的方 差大。
更一般的, 考虑两个估计量 $ T_{n} $ 和 $ U_{n} $, 并且假定
$$ \sqrt{n}\left(T_{n}-\theta\right) \rightsquigarrow N\left(0, t^{2}\right) $$并且
$$ \sqrt{n}\left(U_{n}-\theta\right) \rightsquigarrow N\left(0, u^{2}\right) $$我们定义 $ U $ 相对于 $ T $ 的渐进相对效率为 $ \operatorname{ARE}(U, T)=t^{2} / u^{2} $ 。 在正态估计例题中, $ \operatorname{ARE}\left(\tilde{\theta}_{n}, \widehat{\theta}_{n}\right)=2 / \pi=.63 $ 。对于这个结果的理解 是, 如果使用中值, 只是有效地使用了其中一部分数据。
$ 9.23 $ 定理 如果 $ \widehat{\theta}_{n} $ 是极大似然估计, $ \tilde{\theta}_{n} $ 是其他任意估计,则
$$ \operatorname{ARE}\left(\tilde{\theta}_{n}, \hat{\theta}_{n}\right) \leq 1 $$因此,极大似然估计具有最小渐进方差,称极大似然估计是有效的、渐 进最优的。 这个结论是基于模型正确的假设。如果模型假设本身有误,极大似然估 计就不再是最优的。
Delta 方法
令 $ \tau=g(\theta) $ ,其中 $ g $ 是一个平滑函数。 $ \tau $ 的极大似然估计 $ \widehat{\tau}=g(\widehat{\theta}) $ 。现 在,需要考虑的问题是: $ \widehat{\tau} $ 的分布是什么?
$ 9.24 $ 定理 Delta 方法 如果 $ \tau=g(\theta) $ , 其中, $ g $ 是可微的,且 $ g^{\prime}(\theta) \neq 0 $ , 则
$$ \overbrace{\dfrac{\left(\widehat{\tau}_{n}-\tau\right)}{\operatorname{Se}(\widehat{\tau})}} \rightsquigarrow N(0,1) $$其中, $ \widehat{\tau}_{n}=g\left(\widehat{\theta}_{n}\right) $, 并且,
$$ \widehat{\operatorname{se}}\left(\widehat{\tau}_{n}\right)=\left|g^{\prime}(\widehat{\theta})\right| \widehat{\operatorname{se}\left(\widehat{\theta}_{n}\right)} $$因此, 如果
$$ C_{n}=\left(\widehat{\tau}_{n}-z_{\alpha / 2} \widehat{\operatorname{se}\left(\widehat{\tau}_{n}\right)}, \widehat{\tau}_{n}+z_{\alpha / 2} \widehat{\operatorname{se}\left(\widehat{\tau}_{n}\right)}\right) $$那么, $ \mathbb{P}_{\theta}\left(\tau \in C_{n}\right) \rightarrow 1-\alpha $ ,当 $ n \rightarrow \infty $ 。
令 $ X_{1}, \ldots, X_{n} \sim $ Bernoulli $ (p) $, 并且令 $ \psi=g(p)=\log (p /(1-p)) $ 。Fisher 信息量为 $ I(p)=1 /(p(1-p)) $, 这样, 极大似然估计 $ \widehat{p}_{n} $ 的标准差为
$$ \widehat{\mathrm{se}}=\sqrt{\dfrac{\widehat{p}_{n}\left(1-\widehat{p}_{n}\right)}{n}} $$$ \psi $ 的极大似然估计 $ \widehat{\psi}=\log \widehat{p} /(1-\widehat{p}) $, 由于 $ g^{\prime}(p)=1 /(p(1-p)) $, 因而 根据 Delta 方法,
$$ \widehat{\operatorname{se}}\left(\widehat{\psi}_{n}\right)=\left|g^{\prime}\left(\widehat{p}_{n}\right)\right| \widehat{\operatorname{se}}\left(\widehat{p}_{n}\right)=\dfrac{1}{\sqrt{n \hat{p}_{n}\left(1-\widehat{p}_{n}\right)}} $$一个 $ 95 \% $ 的渐进置信区间为
$$ \widehat{\psi}_{n} \pm \dfrac{2}{\sqrt{n \hat{p}_{n}\left(1-\widehat{p}_{n}\right)}} $$令随机变量 $ X_{1}, \ldots, X_{n} \sim N\left(\mu, \sigma^{2}\right) $ 服从高斯分布。假定均值 $ \mu $ ,已知方 差 $ \sigma $ 末知。我们想要估计 $ \psi=\log \sigma $ 。对数似然函数 $ \ell(\sigma)=-n \log \sigma-\dfrac{1}{2 \sigma^{2}} \sum_{i}\left(x_{i}-\mu\right)^{2} $ 。求导并设置为 0 ,我们得到
$$ \widehat{\sigma}_{n}=\sqrt{\dfrac{\sum_{i}\left(X_{i}-\mu\right)^{2}}{n}} $$为得到标准误差我们需要 Fisher 信息量。首先,
$$ \log f(X ; \sigma)=-\log \sigma-\dfrac{(X-\mu)^{2}}{2 \sigma^{2}} $$进而二阶导数
$$ \dfrac{1}{\sigma^{2}}-\dfrac{3(X-\mu)^{2}}{\sigma^{4}} $$因此,
$$ l(\sigma)=-\dfrac{1}{\sigma^{2}}+\dfrac{3 \sigma^{2}}{\sigma^{4}}=\dfrac{2}{\sigma^{2}} $$因此, $ \widehat{\mathrm{se}}=\widehat{\sigma}_{n} / \sqrt{2 n} $ 。假定 $ \psi=g(\sigma)=\log \sigma $ ,那么 $ \widehat{\psi}_{n}=\log \widehat{\sigma}_{n} $ 。由于 $ g^{\prime}=1 / \sigma $,
$$ \widehat{\operatorname{se}}\left(\widehat{\psi}_{n}\right)=\dfrac{1}{\widehat{\sigma}_{n}} \dfrac{\widehat{\sigma}_{n}}{\sqrt{2 n}}=\dfrac{1}{\sqrt{2 n}} $$这样, 得到一个 $ 95 \% $ 的置信区间是 $ \widehat{\psi}_{n} \pm 2 / \sqrt{2 n} $ 。
以上思想可以很容易扩展到多个参数的情形。假定 $ \theta=\left(\theta_{1}, \ldots, \theta_{k}\right) $ ,其 极大似然估计 $ \widehat{\theta}=\left(\widehat{\theta}_{1}, \ldots, \widehat{\theta}_{k}\right) $ 。令 $ \ell_{n}=\sum_{i=1}^{n} \log f\left(X_{i} ; \theta\right) $,
$$ H_{j j}=\dfrac{\partial^{2} \ell_{n}}{\partial \theta_{j}^{2}} \quad \text { and } \quad H_{j k}=\dfrac{\partial^{2} \ell_{n}}{\partial \theta_{j} \partial \theta_{k}} $$我们定义 Fisher 信息矩阵
$$ I_{n}(\theta)=-\left[\begin{array}{cccc} \mathbb{E}_{\theta}\left(H_{11}\right) & \mathbb{E}_{\theta}\left(H_{12}\right) & \cdots & \mathbb{E}_{\theta}\left(H_{1 k}\right) \\ \mathbb{E}_{\theta}\left(H_{21}\right) & \mathbb{E}_{\theta}\left(H_{22}\right) & \cdots & \mathbb{E}_{\theta}\left(H_{2 k}\right) \\ \vdots & \vdots & \vdots & \vdots \\ \mathbb{E}_{\theta}\left(H_{k 1}\right) & \mathbb{E}_{\theta}\left(H_{k 2}\right) & \cdots & \mathbb{E}_{\theta}\left(H_{k k}\right) \end{array}\right] $$令 $ J_{n}(\theta)=I_{n}^{-1}(\theta) $ 为信息矩阵 $ I_{n}(\theta) $ 的逆矩阵。
多参数模型
以上思想可以很容易扩展到多个参数的情形。假定 $ \theta=\left(\theta_{1}, \ldots, \theta_{k}\right) $ , 其 极大似然估计 $ \widehat{\theta}=\left(\hat{\theta}_{1}, \ldots, \hat{\theta}_{k}\right) $ 。令 $ \ell_{n}=\sum_{i=1}^{n} \log f\left(X_{i} ; \theta\right) $ ,
$$ H_{j j}=\dfrac{\partial^{2} \ell_{n}}{\partial \theta_{j}^{2}} \quad \text { and } \quad H_{j k}=\dfrac{\partial^{2} \ell_{n}}{\partial \theta_{j} \partial \theta_{k}} $$我们定义 Fisher 信息矩阵
$$ I_{n}(\theta)=-\left[\begin{array}{cccc} \mathbb{E}_{\theta}\left(H_{11}\right) & \mathbb{E}_{\theta}\left(H_{12}\right) & \cdots & \mathbb{E}_{\theta}\left(H_{1 k}\right) \\ \mathbb{E}_{\theta}\left(H_{21}\right) & \mathbb{E}_{\theta}\left(H_{22}\right) & \cdots & \mathbb{E}_{\theta}\left(H_{2 k}\right) \\ \vdots & \vdots & \vdots & \vdots \\ \mathbb{E}_{\theta}\left(H_{k 1}\right) & \mathbb{E}_{\theta}\left(H_{k 2}\right) & \cdots & \mathbb{E}_{\theta}\left(H_{k k}\right) \end{array}\right] $$令 $ J_{n}(\theta)=I_{n}^{-1}(\theta) $ 为信息矩阵 $ I_{n}(\theta) $ 的逆矩阵。
在适当的正则条件下,
$$ (\widehat{\theta}-\theta) \approx N\left(0, J_{n}\right) $$并且,如果 $ \widehat{\theta}_{j} $ 是估计 $ \widehat{\theta} $ 的第 $ j $ 成分,则
$$ \dfrac{\left(\widehat{\theta}_{j}-\theta_{j}\right)}{\widehat{\mathrm{se}}_{j}} \rightsquigarrow N(0,1) $$其中, $ \widehat{\mathrm{se}}_{j}^{2}=J_{n}(j, j) $ 为 $ J_{n} $ 的第 $ j $ 个对角元素。 $ \widehat{\theta}_{j} $ 和 $ \widehat{\theta}_{k} $ 的渐进的协方差 为 $ \operatorname{Cov}\left(\widehat{\theta}_{j}, \widehat{\theta}_{k}\right) \approx J_{n}(j, k) $ 。 同样,也有多参数模型的 Delta 方法。令 $ \tau=g\left(\theta_{1}, \ldots, \theta_{k}\right) $ 为一个函数, 令
$$ \nabla g=\left(\begin{array}{c} \dfrac{\partial g}{\partial \theta_{1}} \\ \vdots \\ \dfrac{\partial g}{\partial \theta_{k}} \end{array}\right) $$(多参数的 Delta 方法) 假定 $ \nabla g $ 在 $ \widehat{\theta} $ 处的值为 0 。如果 $ \widehat{\tau}=g(\widehat{\theta}) $, 则
$$ \dfrac{(\widehat{\tau}-\tau)}{\widehat{\operatorname{se}}(\widehat{\tau})} \leadsto N(0,1) $$其中,
$$ \widehat{\operatorname{se}}(\widehat{\tau})=\sqrt{(\widehat{\nabla} g)^{T} \widehat{J}_{n}(\widehat{\nabla} g)} $$其中 $ \widehat{J}_{n}=J_{n}\left(\widehat{\theta}_{n}\right) $, 并且 $ \widehat{\nabla} g $ 是 $ \nabla g $ 在 $ \theta=\widehat{\theta} $ 的估计。
令 $ X_{1}, \ldots, X_{n} \sim N\left(\mu, \sigma^{2}\right) $, 令 $ \tau=g(\mu, \sigma)=\sigma / \mu $ 。如果能够证明 $ ( $ 习题 8)
$$ I_{n}(\mu, \sigma)=\left[\begin{array}{cc} \dfrac{n}{\sigma^{2}} & 0 \\ 0 & \dfrac{2 n}{\sigma^{2}} \end{array}\right] $$因此,
$$ J_{n}=I_{n}^{-1}(\mu, \sigma)=\dfrac{1}{n}\left[\begin{array}{cc} \sigma^{2} & 0 \\ 0 & \dfrac{\sigma^{2}}{2} \end{array}\right] $$$ g $ 函数的梯度为
$$ \nabla g=\left(\begin{array}{c} -\dfrac{\sigma}{\mu^{2}} \\ \dfrac{1}{\mu} \end{array}\right) $$这样,
$$ \widehat{\operatorname{se}(\widehat{\tau})}=\sqrt{(\widehat{\nabla} g)^{\top} \widehat{J}(\widehat{\nabla} g)}=\dfrac{1}{\sqrt{n}} \sqrt{\dfrac{1}{\widehat{\mu}^{4}}+\dfrac{\widehat{\sigma}^{2}}{2 \widehat{\mu}^{2}}} $$对于参数化模型,标准差和置信区间都可以使用 Bootstrap 方法估计。 这里仅仅有一个变化。在非参数的 Bootstrap 方法中,我们从经验分布 $ \widehat{F}_{n} $ 中抽取 $ X_{1}^{_}, \ldots, X_{n}^{_} $ 。而在参数化模型的 Bootstrap 中,我们从参数模 型 $ f\left(x ; \hat{\theta}_{n}\right) $ 中抽样。这里, $ \widehat{\theta}_{n} $ 可以是极大似然估计或矩估计。
考虑 $ 9.29 $ 例题。为了得到 bootstrap 的标准误差, 我们仿真 $ X_{1}, \ldots, X_{n}^{_} \sim N\left(\widehat{\mu}, \widehat{\sigma}^{2}\right) $, 计算 $ \widehat{\mu}^{_}=n^{-1} \sum_{i} X_{i}^{_} $ 和 $ \widehat{\sigma}^{2 _}=n^{-1} \sum_{i}\left(X_{i}^{_}-\widehat{\mu}^{_}\right)^{2} $ 。然后我们计算 $ \widehat{\tau}^{_}=g\left(\widehat{\mu}^{_}, \widehat{\sigma}^{_}\right)=\widehat{\sigma}^{_} / \widehat{\mu}^{_} $ 。重复 $ B $ 次,就产生 Bootstrap 抽样组,
$$ \widehat{\tau}_{1}^{_}, \ldots, \widehat{\tau}_{B}^{*} $$然后我们估计
$$ \widehat{\text { se boot }}=\sqrt{\dfrac{\sum_{b=1}^{B}\left(\widehat{\tau}_{b}^{*}-\widehat{\tau}\right)^{2}}{B}} $$我们看到,Bootstrap 方法要比 Delta 方法简单。但另一方面,Delta 方 法给出了标准差估计的封闭解。
检验假设条件
如果假设数据来自某个参数化模型,那么检查这个假设是否成立是一个 很好的想法。一种方法是通过查看数据的分布图,这种方法不够严格。 例如,如果数据的柱状图是双峰分布,显然使用正态分布的假设就存在 问题。一个更为正式的方法是使用拟合优度检测方法 (Goodness-of-fit Test)来检查参数化模型的假设 (10.8 节)。