GAN 生成手写数字和 Pokemon 实战
目标
-
搭建和训练 GAN 生成手写数字的模型
-
观察效果和 Loss 情况
-
训练模型生成宝可梦精灵
基础概念
JS 散度
$$ J S\left(P_{1} \| P_{2}\right)=\frac{1}{2} K L\left(P_{1} \| \frac{P_{1}+P_{2}}{2}\right)+\frac{1}{2} K L\left(P_{2} \| \frac{P_{1}+P_{2}}{2}\right) $$基于 KL散度的变体,解决了KL散度非对称的问题
GAN
对抗生成网络,包括一个生成模型 (generative model) 和一个判别模型 (discriminative model)。生成器用于生成假样本,判别器用于判断样本真假。训练目标:生成的假样本被判定为真:假的概率为 1:1.
-
记 D 为判别器,G 为生成器。
-
判别模型:是一个二分类器(看作0-1二分类),用于判断样本是真是假;(分类器输入为样本,输出概率大于0.5为真,否则为假)
-
生成模型:是一个样本生成器,把一个噪声包装成另一个逼真的样本,使得判别器误认为是真样本;(输入为噪声,输出为样本维度相同的噪声(假样本))
目的
-
输入:真实样本
-
有监督:真实样本为 1,假样本为 0
-
输出:生成逼真的假样本
如果 G 搞出一些假数据,骗过了 D 的法眼(即符合样本的真实分布 P_data(x)),则我们成功地生成了一些假数据。
那我们就要调整参数,使得这俩分布尽量接近。
怎么调整参数呢?我们把真假数据 x_data, x_gen 都送给 D 中训练,D 对齐进行二分类(真、假)。
然后我们既要二分类准确,又要生成器拟真,这就是对抗的由来。接下来就是祭出公式
$$ \min_{G} \max_{D} V\left(D, G\right) = \mathbb{E}_{\boldsymbol{x} \sim p_{data}{\left(\boldsymbol{x}\right)}}{\left[\log D\left(\boldsymbol{x}\right)\right]} + \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}\left(\boldsymbol{z}\right)}{\left[\log \left(1 - D\left(G\left(\boldsymbol{z}\right)\right)\right)\right]} $$-
x 表示真实图片
-
z 表示输入 G 网络的噪声
-
而G(z)表示G网络生成的图片。
-
D(x) 表示D网络判断真实图片是否真实的概率,所以对于D来说,这个值越接近1越好
-
而 D(G(z))是D 网络认为假图有多真。
对于 G 而言:
-
G的目的:让 D(G(z)) 更大。
- 这时 V(D, G)会变小。因此式子的最前面的记号是min_G。
-
D的目的:让 D(G(x)) 更小。
- 这时V(D,G)会变大。因此式子对于D来说是求最大 max_D
带入 $V(D,G)$ 得到
$$ V=\int_{x} p_{\text {data }}(x) \log \frac{\frac{1}{2} p_{\text {data }}(x)}{\frac{p_{\text {data }}(x)+p_{G}(x)}{2}}+p_{G}(x) \log \frac{\frac{1}{2} p_{G}(x)}{\frac{p_{\text {data }}(x)+p_{G}(x)}{2}} d x $$由 $K L(P \| Q)=\sum_{x \in X} P(x) \log \frac{P(x)}{Q(x)}$, 得上式为:
$$ V = -2 \log 2+K L\left(p_{\text {data }} \| \frac{p_{\text {data }}(x)+p_{G}(x)}{2}\right)+K L\left(p_{G} \| \frac{p_{\text {data }}(x)+p_{G}(x)}{2}\right) $$这右边俩 KL 加起来不就是 JS 散度。
GAN 模型的设计
导入依赖
1import tensorflow as tf
2from tensorflow import keras
3from tensorflow.keras import layers
4import matplotlib.pyplot as plt
5
6%matplotlib inline
7import numpy as np
初始化参数和训练样本
1(train_images, train_labels),(_, _) = tf.keras.datasets.mnist.load_data()
2print(train_images.shape)
3train_images = tf.expand_dims(train_images, -1)
4print(train_images.shape)
5train_images = tf.cast(train_images, tf.float32)
6
7print(train_images.dtype)
8train_images = (train_images - 127.5)/127.5 # 归一化到[-1,1]
9print(train_images.shape)
打乱训练样本
1BATCH_SIZE = 64
2# 创建数据集
3datasets = tf.data.Dataset.from_tensor_slices(train_images)
4datasets = datasets.shuffle(60000).batch(BATCH_SIZE) # (64, 28, 28)
生成器
1
2generator = tf.keras.Sequential(layers=[
3 # 一个100维的随机向量作为输入
4 layers.Dense(7 * 7 * 256, use_bias=False, input_shape=(100,)),
5 layers.BatchNormalization(),
6 layers.LeakyReLU(),
7 layers.Reshape((7, 7, 256)), # (None, 7, 7, 256) None 表示批大小
8
9 layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False), # (None, 7, 7, 128)
10 layers.BatchNormalization(),
11 layers.LeakyReLU(),
12
13 layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False), # (None, 14, 14, 64)
14 layers.BatchNormalization(),
15 layers.LeakyReLU(),
16
17 layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh') # (None, 28, 28, 1)
18])
19
20tf.keras.utils.plot_model(generator, show_shapes=True)
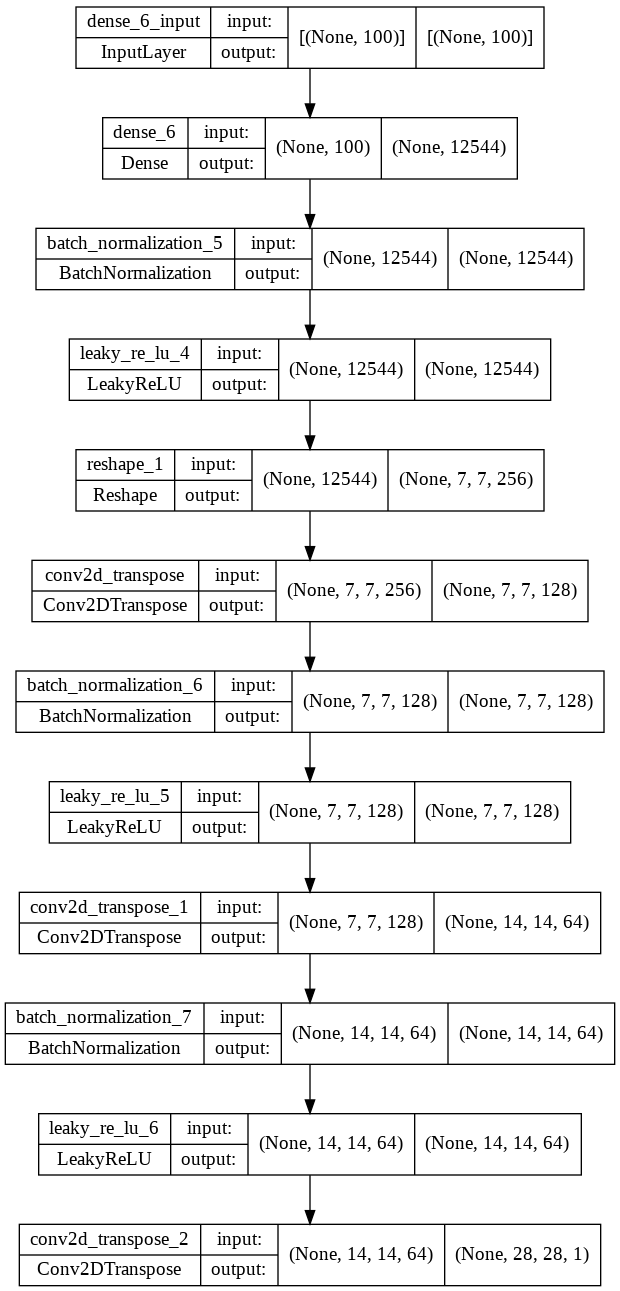
判别器
1discriminator = tf.keras.Sequential(layers=[
2 layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', input_shape=[28, 28, 1]),
3 layers.LeakyReLU(),
4 layers.Dropout(0.3),
5 layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'),
6 layers.LeakyReLU(),
7 layers.Dropout(0.3),
8 layers.Flatten(),
9 layers.Dense(1)
10])
11
12# 设置交叉熵函数
13# logits 表示网络的直接输出,没经过 sigmoid 或者 softmax 的概率化。
14# from_logits=False 就表示把已经概率化了的输出,重新映射回原值,那么 =True 就是上面没有经过概率化输出
15
16cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
17
18tf.keras.utils.plot_model(generator, show_shapes=True)
损失函数
1# 判别器损失
2# real_output 其实就是一个批次的输出结果,形状是 (BATCH_SIZE, 1)
3# fake_output 是预测的输出,形状一样
4def discriminator_loss(real_output, fake_output):
5 # 通过真实样本损失和假样本损失相加得到
6 # ones_like 就是按形状创建全 1 张量
7 # zeros_like 就是按形状创建全 0 张量
8 # 真实的图像希望能判别为1,生成的图像希望能判别为0
9 real_loss = cross_entropy(tf.ones_like(real_output), real_output)
10 fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
11 total_loss = real_loss + fake_loss
12 return total_loss
13
14# 生成器损失
15def generator_loss(fake_output):
16 # 希望生成的假图和 1 越来越像
17 return cross_entropy(tf.ones_like(fake_output), fake_output)
优化器
1# 生成器和判别器是两个模型,所以设置两个分别的优化器
2generator_optimizer = tf.keras.optimizers.Adam(1e-4)
3discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
GAN 模型封装,指标追踪
1noise_dim = 100
2
3class GAN(keras.Model):
4 def __init__(self, generator, discriminator, **kwargs):
5 super(GAN, self).__init__(**kwargs)
6 self.generator = generator
7 self.discriminator = discriminator
8 # 记录生成器损失
9 self.gen_loss_tracker = keras.metrics.Mean(name="gen_loss")
10 # 记录判别器损失
11 self.disc_loss_tracker = keras.metrics.Mean(name="disc_loss")
12
13 @property
14 def metrics(self):
15 return [
16 self.gen_loss_tracker,
17 self.disc_loss_tracker
18 ]
19
20 def train_step(self, images): # 接受一个批次的图像(64, 28, 28, 1)
21 noise = tf.random.normal([BATCH_SIZE, noise_dim]) #(64, 100)
22 with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape: #要追踪两个model的梯度
23
24 gen_image = self.generator(noise, training=True)#返回(64,28,28,1)
25
26 real_out = self.discriminator(images, training=True) # 把images(64, 28, 28, 1)送入判别器返回(64,1) 64是64张图像,1是每个图像的返回结果, 因为最后之后一个神经元
27 fake_out = self.discriminator(gen_image, training=True) # 把生成的图像(64,28,28,1),送入判别器得到(64, 1)
28
29 # 以上都是为了得到loss, 通过记录loss的获得流程, 最终通过调整参数利用优化器, 降低loss
30 gen_loss = generator_loss(fake_out) # 生成器希望让生成图像被判别为真
31 disc_loss = discriminator_loss(real_out, fake_out)
32
33 gradient_gen = gen_tape.gradient(gen_loss, self.generator.trainable_variables)#计算生成器损失和生成器变量之间的梯度
34 gradient_disc = disc_tape.gradient(disc_loss, self.discriminator.trainable_variables)#计算判别器损失和生成器变量之间的梯度
35
36 #更新参数
37 generator_optimizer.apply_gradients(zip(gradient_gen, self.generator.trainable_variables))
38 discriminator_optimizer.apply_gradients(zip(gradient_disc, self.discriminator.trainable_variables))
39
40 self.gen_loss_tracker.update_state(gen_loss)
41 self.disc_loss_tracker.update_state(disc_loss)
42
43 return {
44 "gen_loss": self.gen_loss_tracker.result(),
45 "disc_loss": self.disc_loss_tracker.result()
46 }
训练
训练过程:
-
先将真实图片和由噪声向量生成的伪图片分别传入 Discriminator
-
输出的概率分别与真实图片 label(都为1)和伪图片 label(都为O)计算交叉嫡(cross entropy),并进行反向传播来对Discriminator 进行优化。
-
然后再由噪声图片经生成器 Generator 生成伪图片该入 .Discrimator,输出概率与真实图片label(都为1)计算交叉嫡,并反向传播,对生成器Generator进行优化。
-
最终达到在提高生成器Generator生成图片质量的同时,保证 Discriminator 判别其为真。
1# 开始炼丹
2gan = GAN(generator, discriminator)
3gan.compile(optimizer=keras.optimizers.Adam())
4
5history = gan.fit(datasets, epochs=40, batch_size=128)
Loss 变化
1# 显示指标变化
2import pandas as pd
3pd.DataFrame(gan.history.history).plot(figsize=(8,4))
训练 40 代的 Loss 变化:
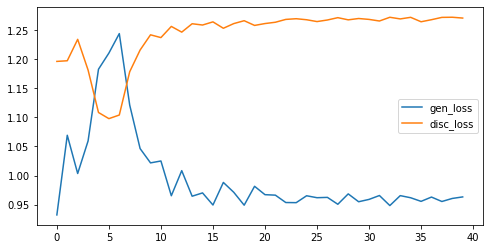
可以看到第五代的时候,生成损失短暂增加,之后每次损失都会减少。而判别器损失在第五代的时候会减少,之后每次损失都会减少。
训练 100 代的 Loss 变化:
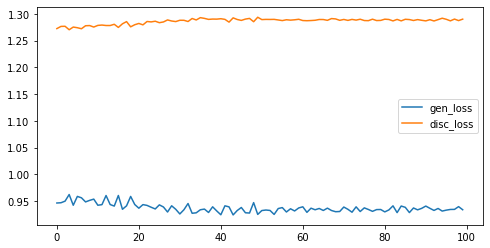
后面基本是在震荡,但是从效果来看,生成效果有明显提升。
这说明即便 Loss 不变,模型也在变得更好。
生成效果
我们从随机噪声生成。
1def demo(model, z):
2 predictions = model(z, training=False)
3
4 fig = plt.figure(figsize=(8,8))
5 n = z.shape[0]
6 nsqrt = int(np.sqrt(n))
7 for i in range(1, n+1):
8 plt.subplot(nsqrt, nsqrt, i)
9 plt.imshow(predictions[i-1, :, :, 0] * 127.5 + 127.5, cmap='viridis')
10 plt.axis('off')
11
12 plt.show()
13z = tf.random.normal([64, noise_dim])
14# 随机生成一些样本
15demo(generator, z)
训练 50 代的生成效果

训练 100 代的生成效果

生成 Pokemon Sprites
生成 Pokemon Sprites 还是有一点挑战的:
-
在现实世界中,一般还是用彩色图片比较多。彩色图片的特点就是有三个通道。第一个难点是,怎么调整网络来适应彩色的图片。
-
第二个难点是数据集少。我们只能加大训练代数来弥补。
下面开始正文。
下载和查看数据集
下载数据集
1!wget http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Pokemon_creation/image.rar
2!pip install unrar
解压,将会放到 figure 目录
!unrar x image.rar
# list first 10
!ls -l figure | head -n 10
1total 3176
2-rw-r--r-- 1 root root 1124 Nov 19 2016 001MS.png
3-rw-r--r-- 1 root root 1182 Nov 19 2016 002MS.png
4-rw-r--r-- 1 root root 790 Nov 19 2016 003MMS.png
5-rw-r--r-- 1 root root 1322 Nov 19 2016 003MS.png
6-rw-r--r-- 1 root root 1114 Nov 19 2016 004MS.png
7-rw-r--r-- 1 root root 1134 Nov 19 2016 005MS.png
8-rw-r--r-- 1 root root 1247 Nov 19 2016 006MS.png
9-rw-r--r-- 1 root root 4168 Nov 19 2016 006MXMS.png
10-rw-r--r-- 1 root root 1304 Nov 19 2016 006MYMS.png
看看图片有多大?
1import cv2
2# 图片大小
3for i in [
4"001MS.png",
5"002MS.png",
6"003MMS.png",
7"003MS.png",
8]:
9 img = cv2.imread(f"figure/{i}")
10 print(img.shape)
1(40, 40, 3)
2(40, 40, 3)
3(40, 40, 3)
4(40, 40, 3)
好,看起来不大,我们的廉价 GPU 逃过一劫。
载入模型并预处理
1
2import glob
3# 载入模型
4# 列出目录下所有 png 文件,并将其转换为 tf.data.Dataset
5def load_dataset(path = 'figure'):
6 def load_and_preprocess_image(path):
7 img = tf.io.read_file(path)
8 img = tf.image.decode_png(img, channels=3)
9 # 归一化到 [0, 1]
10 img = tf.image.convert_image_dtype(img, tf.float32)
11 img = tf.image.resize(img, [40, 40])
12 # 归一化到 [-1, 1]
13 img = (img - 0.5)*2.0
14 return img
15 files = glob.glob(path + '/*.png')
16 all_image_paths = list(files)
17 print("we have {} images".format(len(all_image_paths)))
18 all_image_paths = [str(path) for path in all_image_paths]
19 rgb_image_ds = np.array([load_and_preprocess_image(path) for path in all_image_paths])
20 return rgb_image_ds
21
22img_ds = load_dataset()
23print(img_ds.shape)
24print(img_ds[0])
we have 792 images
(792, 40, 40, 3)
[[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]
...
[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]
...
[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]
...
[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
...
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]
...
[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]
...
[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]
...
[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]]
和 VAE 的不同之处是,GAN 需要归一化到 [-1, 1]
1# 批大小
2BATCH_SIZE = 256
3# 为输入张量的每一行创建数据集
4datasets = tf.data.Dataset.from_tensor_slices(x_train)\
5 .shuffle(len(x_train))\
6 .batch(BATCH_SIZE)
至此数据集有了。
预览一下数据集
1#preview first 4 images
2import matplotlib.pyplot as plt
3
4plt.figure(figsize=(8, 8))
5for i in range(4):
6 plt.subplot(2, 2, i + 1)
7 plt.imshow(img_ds[i])
8plt.show()

生成器模型
为了适应新的图片大小和颜色通道,需要略作调整。
1generator = tf.keras.Sequential(name="generator", layers=[
2 layers.Dense(10 * 10 * 256, use_bias=False, input_shape=(100,)),
3 layers.BatchNormalization(),
4 layers.LeakyReLU(),
5 layers.Reshape((10, 10, 256)), # (None, 10, 10, 256) None 表示批大小
6
7 layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False), # (None, 10, 10, 128)
8 layers.BatchNormalization(),
9 layers.LeakyReLU(),
10
11 layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False), # (None, 14, 14, 64)
12 layers.BatchNormalization(),
13 layers.LeakyReLU(),
14
15 layers.Conv2DTranspose(3, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh') # (None, 40, 40, 3)
16])
17
18tf.keras.utils.plot_model(generator, show_shapes=True)
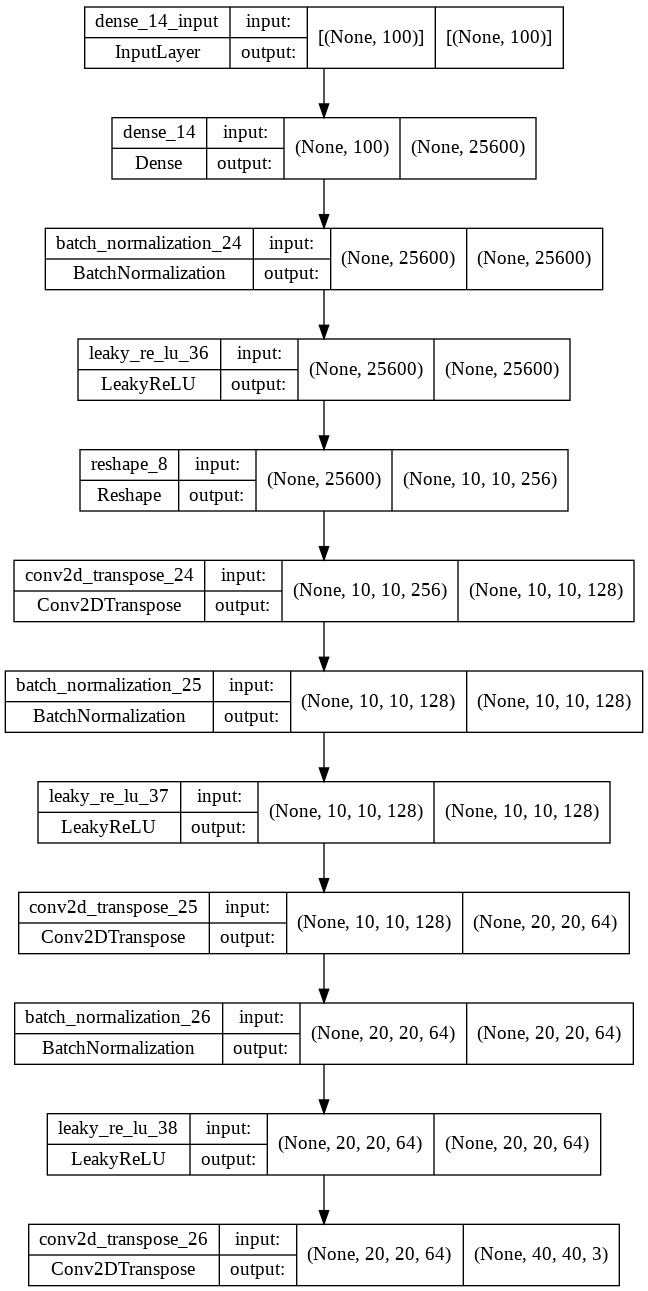
判别器模型
为了适应新的图片大小和颜色通道,需要略作调整。
需要注意的是这里改成了 MSE 作为误差函数。
1discriminator = tf.keras.Sequential(name="discriminator", layers=[
2 layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', input_shape=[40, 40, 3]),
3 layers.LeakyReLU(),
4 layers.Dropout(0.3),
5 layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'),
6 layers.LeakyReLU(),
7 layers.Dropout(0.3),
8 layers.Flatten(),
9 layers.Dense(1)
10])
11
12# 彩色,所以改用 MSE
13cross_entropy = tf.keras.losses.MeanSquaredError()
14
15tf.keras.utils.plot_model(generator, show_shapes=True)
模型封装
1# 训练代数
2EPOCHS = 5000
3# 噪声维度,就是随机生成的向量的长度
4noise_dim = 100
5# 随机种子
6seed = tf.random.normal([16, noise_dim]) # 16 代表随机样本数量
7
8
9from tensorflow import keras
10class GAN(keras.Model):
11 def __init__(self, generator, discriminator, **kwargs):
12 super(GAN, self).__init__(**kwargs)
13 self.generator = generator
14 self.discriminator = discriminator
15 # 记录生成器损失
16 self.gen_loss_tracker = keras.metrics.Mean(name="gen_loss")
17 # 记录判别器损失
18 self.disc_loss_tracker = keras.metrics.Mean(name="disc_loss")
19
20 @property
21 def metrics(self):
22 return [
23 self.gen_loss_tracker,
24 self.disc_loss_tracker
25 ]
26
27 def train_step(self, images): # 接受一个批次的图像(64, 40, 40, 1)
28 noise = tf.random.normal([BATCH_SIZE, noise_dim]) #(64, 100)
29 with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape: #要追踪两个model的梯度
30
31 gen_image = self.generator(noise, training=True)#返回(64, 40,40 ,3)
32
33 real_out = self.discriminator(images, training=True) # 把images(64, 40, 40, 1)送入判别器返回(64,1) 64是64张图像,1是每个图像的返回结果, 因为最后之后一个神经元
34 fake_out = self.discriminator(gen_image, training=True) # 把生成的图像(64, 40,40 ,3),送入判别器得到(64, 1)
35
36 # 以上都是为了得到loss, 通过记录loss的获得流程, 最终通过调整参数利用优化器, 降低loss
37 gen_loss = generator_loss(fake_out) # 生成器希望让生成图像被判别为真
38 disc_loss = discriminator_loss(real_out, fake_out)
39
40 gradient_gen = gen_tape.gradient(gen_loss, self.generator.trainable_variables)#计算生成器损失和生成器变量之间的梯度
41 gradient_disc = disc_tape.gradient(disc_loss, self.discriminator.trainable_variables)#计算判别器损失和生成器变量之间的梯度
42
43 #更新参数
44 generator_optimizer.apply_gradients(zip(gradient_gen, self.generator.trainable_variables))
45 discriminator_optimizer.apply_gradients(zip(gradient_disc, self.discriminator.trainable_variables))
46
47 self.gen_loss_tracker.update_state(gen_loss)
48 self.disc_loss_tracker.update_state(disc_loss)
49
50 return {
51 "gen_loss": self.gen_loss_tracker.result(),
52 "disc_loss": self.disc_loss_tracker.result()
53 }
开始训练
1gan = GAN(generator, discriminator)
2gan.compile(optimizer=keras.optimizers.Adam())
3
4history = gan.fit(datasets, epochs=EPOCHS, batch_size=BATCH_SIZE)
gen loss 和 disc loss 变化
1# 显示指标变化
2import pandas as pd
3pd.DataFrame(gan.history.history).plot(figsize=(8,4))
100 代
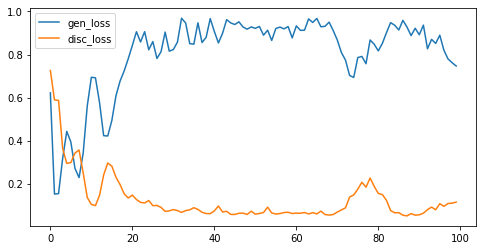
5000 代
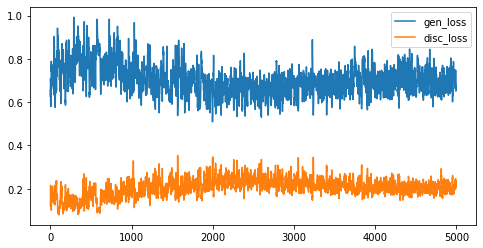
效果
1noise = tf.random.normal([64, noise_dim])
2# 随机生成一些样本
3pred = generator(noise, training=False)
4fig = plt.figure(figsize=(8,8))
5n = 64
6nsqrt = int(np.sqrt(n))
7for i in range(1, n+1):
8 plt.subplot(nsqrt, nsqrt, i)
9 plt.imshow(((pred / 2 +0.5))[i-1])
10 plt.axis('off')
11plt.show()
训练 100 代

训练 5000 代

最终效果还是不错的,感觉比 VAE 好。
参考资料
深度卷积生成对抗网络 | TensorFlow Core 这是 Keras 官方文档。
Day 27:使用Keras撰寫 生成式對抗網路(GAN) 这篇文章介绍了生成动漫头像的方法