Spark 及 Hive 离线批处理实践
目标
从 Hive 读取数据并进行词频统计
Hadoop 集群环境测试
状态测试
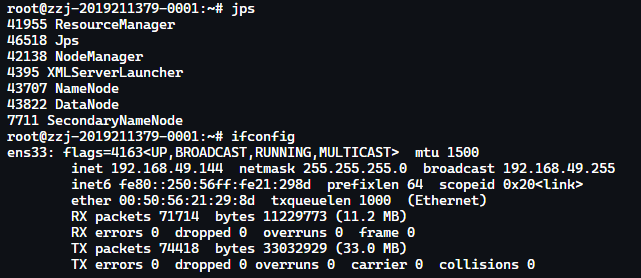
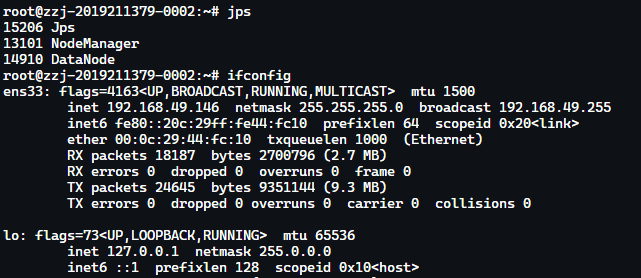
可用性测试
1hadoop jar /var/local/hadoop/hadoop-3.3.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.2.jar pi 10 10
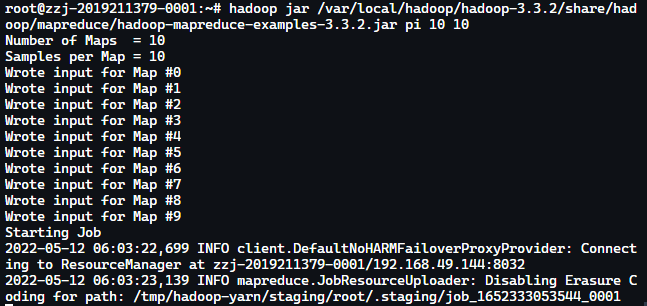
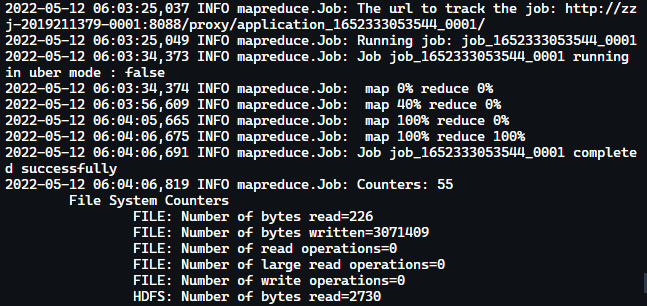
Yarn Spark 集群搭建
[master] Spark 的下载
cd ~
wget https://dlcdn.apache.org/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2.tgz
安装
mkdir /var/local/spark
tar zxvf spark-3.2.1-bin-hadoop3.2.tgz -C /var/local/spark
/var/local/spark/spark-3.2.1-bin-hadoop3.2/
[master] 设置环境变量
1 vi ~/.profile
加入以下内容:
1export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
2export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
3export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
4export PATH=$PATH:/var/local/spark/spark-3.2.1-bin-hadoop3.2/bin
- 运行
source命令,使添加变量生效:
1source .bash_profile
[master] yarn-site.xml
cd /var/local/hadoop/hadoop-3.3.2/etc/hadoop/
code yarn-site.xml
增加
1 <property>
2 <name>yarn.nodemanager.pmem-check-enabled</name>
3 <value>false</value>
4 </property>
5 <property>
6 <name>yarn.nodemanager.vmem-check-enabled</name>
7 <value>false</value>
8 </property>
发送到从节点
1
2scp yarn-site.xml zzj-2019211379-0002:/var/local/hadoop/hadoop-3.3.2/etc/hadoop/yarn-site.xml
3scp yarn-site.xml zzj-2019211379-0003:/var/local/hadoop/hadoop-3.3.2/etc/hadoop/yarn-site.xml
4scp yarn-site.xml zzj-2019211379-0004:/var/local/hadoop/hadoop-3.3.2/etc/hadoop/yarn-site.xml
重启 Hadoop 集群
1stop-all.sh
2start-all.sh
使用 jps 检查是否启动成功
运行以下指令检查 spark 是否部署成功
1sudo chmod -R 777 /var/local/spark/spark-3.2.1-bin-hadoop3.2/
2spark-submit --class org.apache.spark.examples.SparkPi --master yarn --num-executors 4 --driver-memory 1g --executor-memory 1g --executor-cores 1 /var/local/spark/spark-3.2.1-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.2.1.jar
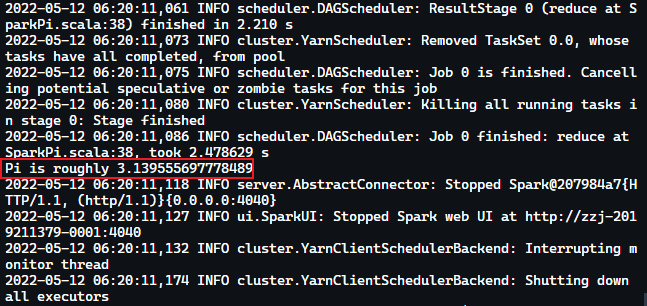
- 运行
spark-shell命令,查看 spark 和 scala 版本信息
1spark-shell
测试 Scala 程序
创建 Project
Maven 配置
1<?xml version="1.0" encoding="UTF-8"?>
2<project xmlns="http://maven.apache.org/POM/4.0.0"
3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
5 <modelVersion>4.0.0</modelVersion>
6
7 <groupId>org.example</groupId>
8 <artifactId>spark-test</artifactId>
9 <version>1.0-SNAPSHOT</version>
10
11 <properties>
12 <maven.compiler.source>8</maven.compiler.source>
13 <maven.compiler.target>8</maven.compiler.target>
14
15 <scala.version>2.12.15</scala.version>
16 <spark.version>3.2.1</spark.version>
17 </properties>
18
19 <dependencies>
20 <dependency>
21 <groupId>org.apache.spark</groupId>
22 <artifactId>spark-core_2.12</artifactId>
23 <version>${spark.version}</version>
24 </dependency>
25 <dependency>
26 <groupId>org.apache.spark</groupId>
27 <artifactId>spark-sql_2.12</artifactId>
28 <version>${spark.version}</version>
29 </dependency>
30 <dependency>
31 <groupId>org.scala-tools</groupId>
32 <artifactId>maven-scala-plugin</artifactId>
33 <version>2.11</version>
34 </dependency>
35 <dependency>
36 <groupId>org.apache.maven.plugins</groupId>
37 <artifactId>maven-eclipse-plugin</artifactId>
38 <version>2.5.1</version>
39 </dependency>
40 </dependencies>
41</project>
代码编写
将默认类重命名为 ScalaWordCount,代码如下:
1package org.example
2
3import org.apache.spark.rdd.RDD
4import org.apache.spark.{SparkConf, SparkContext}
5
6class ScalaWordCount {
7
8}
9object ScalaWordCount{
10 def main(args: Array[String]): Unit = {
11 val list=List("hello hi hi spark", "hello spark hello hi sparksql", "hello hi hi sparkstreaming", "hello hi sparkgraphx")
12 val sparkConf = new SparkConf().setAppName("word-count").setMaster("yarn")
13 val sc = new SparkContext(sparkConf)
14 // 将 list 转换成 RDD
15 val lines:RDD[String]=sc.parallelize(list)
16 // 将 RDD 中的每一行单词进行空格切分
17 val words:RDD[String]=lines.flatMap((line:String)=>line.split(" "))
18 // 将单词进行转换,将单词转换成 (单词, 1)
19 val wordAndOne:RDD[(String,Int)]=words.map((word:String)=>(word,1))
20 // 将相同单词进行聚合
21 val wordAndNum:RDD[(String,Int)]=wordAndOne.reduceByKey((x:Int,y:Int)=>x+y)
22 // 按照单词出现的次数进行排序
23 val ret=wordAndNum.sortBy(kv=>kv._2,false)
24 // 打印结果
25 print(ret.collect().mkString(","))
26 // 保存结果
27 ret.saveAsTextFile("hdfs://zzj-2019211379-0001:8020/spark-test")
28 sc.stop()
29 }
30}
4.4 程序打包与运行
打包 JAR From Module
编辑 JAR,删除其中 META-INF/MANIFEST.MF
提交到 hadoop spark 执行
Host
scp C:\Repo\big-data\spark-test\out\artifacts\spark_test_jar\spark-test.jar root@zzj-2019211379-0001:~
1spark-submit --class org.example.ScalaWordCount --master yarn --num-executors 3 --driver-memory 1g --executor-memory 1g --executor-cores 1 spark-test.jar
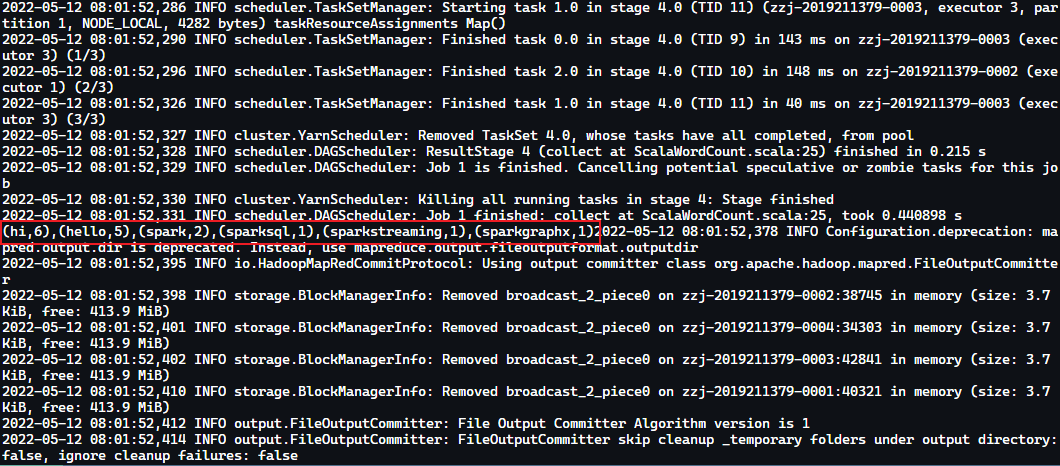
在 hdfs 上查看程序的输出
1hadoop fs -cat /spark-test/part-00000
使用 hive 数据源进行 wordcount
安装 MySQL 5.7
参考 How to Install MySQL 5.7 on Ubuntu 20.04 - Vultr.com
有问题就看 /var/log/mysql/error.log
修改 root 默认密码
1sudo mysql_secure_installation
关闭密码策略
编码配置
[mysqld]
init_connect='SET NAMES utf8'
[client]
default-character-set=utf8
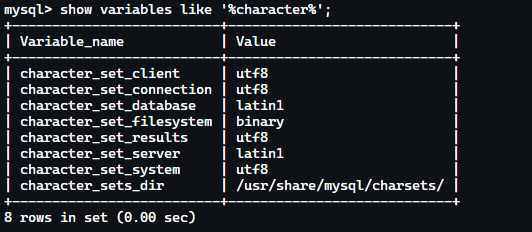
查看编码
mysql -uroot -p
show variables like '%character%';
下载安装 Hive
1wget https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
2mkdir /var/local/hive
3tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /var/local/hive
创建 Hadoop 的 MySQL 用户
1grant all on *.* to hadoop@'%' identified by 'hadoop';
2grant all on*.* to hadoop@'localhost' identified by 'hadoop';
3grant all on *.* to hadoop@'master' identified by 'hadoop';
4flush privileges;
1mysql -uroot -p
2CREATE USER 'hadoop'@'localhost' IDENTIFIED BY 'hadoop';
3use mysql;
4update user set host = '%' where user = 'root';
5update user set host = '%' where user = 'hadoop';
6flush privileges ;
7mysql> select host, grant_priv, user from user;
8+-----------+------------+------------------+
9| host | grant_priv | user |
10+-----------+------------+------------------+
11| % | N | hadoop |
12| % | Y | root |
13| localhost | Y | debian-sys-maint |
14| localhost | N | mysql.infoschema |
15| localhost | N | mysql.session |
16| localhost | N | mysql.sys |
17+-----------+------------+------------------+
186 rows in set (0.00 sec)
19grant all on *.* to 'hadoop';
% 表示允许从任何主机登录。
1create database hive;
配置 Hive
进入配置目录
1cd /var/local/hive/apache-hive-3.1.3-bin/conf/
创建 hive 配置文件:
1code hive-site.xml
添加如下内容
1<?xml version="1.0"?>
2<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3<configuration>
4 <property>
5 <name>hive.metastore.local</name>
6 <value>true</value>
7 </property>
8 <property>
9 <name>javax.jdo.option.ConnectionURL</name>
10 <value>jdbc:mysql://zzj-2019211379-0001:3306/hive?characterEncoding=UTF-8</value>
11 </property>
12 <property>
13 <name>javax.jdo.option.ConnectionDriverName</name>
14 <value>com.mysql.jdbc.Driver</value>
15 </property>
16 <property>
17 <name>javax.jdo.option.ConnectionUserName</name>
18 <value>hadoop</value>
19 </property>
20 <property>
21 <name>javax.jdo.option.ConnectionPassword</name>
22 <value>hadoop</value>
23 </property>
24 <property>
25 <name>hive.server2.authentication</name>
26 <value>NOSASL</value>
27 </property>
28 <property>
29 <name>hive.server2.enable.doAs</name>
30 <value>false</value>
31 </property>
32</configuration>
上传 MySQL 连接驱动
将
mysql-connector-java-5.1.28.jar上传至/root
复制 MySQL 连接驱动到 hive 根目录下的 lib 目录中
1scp mysql-connector-java-5.1.28.jar root@zzj-2019211379-0001:/var/local/hive/apache-hive-3.1.3-bin/lib

配置环境变量
1code /root/.profile
加入以下内容
1export HIVE_HOME=/var/local/hive/apache-hive-3.1.3-bin
2export PATH=$PATH:$HIVE_HOME/bin
使环境变量生效
1. /root/.profile
启动并验证 Hive 安装
初始化 Hive 元数据库
1schematool -dbType mysql -initSchema --verbose
如果出现导入错误。检查上述命令的输出是否含有
jdbc:derby:;databaseName=metastore_db;create=true,若是,说明连接字符串配置不对。应为:
jdbc:mysql://zzj-2019211379-0001:3306/hive?characterEncoding=UTF-8
如果出现
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.,则是 Hadoop mysql 账号配置不对。
如果出现
Caused by: java.net.ConnectException: Connection refused (Connection refused)则看一下 3306 监听 IP 是否是内网 IP。增加:bind-address=0.0.0.0 # skip-networking到
cnf的[mysqld]section, thenservice mysql restart
修改 Hadoop 集群配置
core-site.xml
code /var/local/hadoop/hadoop-3.3.2/etc/hadoop/core-site.xml
加入以下内容
1 <property>
2 <name>hadoop.proxyuser.root.hosts</name>
3 <value>*</value>
4 </property>
5 <property>
6 <name>hadoop.proxyuser.root.groups</name>
7 <value>*</value>
8 </property>
开启 Hive 远程模式
1hive --service metastore &
2hive --service hiveserver2 &
Hive 建库并导入数据
上传 text.txt 至 /root
scp .\text.txt root@zzj-2019211379-0001:~
将文件导入 hdfs
1cd ~
2hadoop fs -mkdir -p /spark/wordcount
3hadoop fs -put text.txt /spark/wordcount
使用 hive 命令进入 hive 命令行进行建库和数据导入操作
1hive
在 hive 窗口中执行以下命令
1create database spark;
2use spark;
3create external table wordcount(content string) STORED AS TEXTFILE LOCATION '/spark/wordcount';
4select * from wordcount limit 10;
修改 wordcount 程序
将代码整体替换为
1package org.example
2
3import org.apache.spark.rdd.RDD
4import org.apache.spark.sql.jdbc.{JdbcDialect, JdbcDialects}
5import org.apache.spark.sql.{Row, SparkSession}
6import org.apache.spark.{SparkConf, SparkContext}
7
8class ScalaWordCount {
9
10}
11object ScalaWordCount{
12 def main(args: Array[String]): Unit = {
13 val spark = SparkSession.builder().appName("word-count").getOrCreate()
14 register()
15 val df = spark.read
16 .format("jdbc")
17 .option("driver","org.apache.hive.jdbc.HiveDriver")
18 .option("url","jdbc:hive2://zzj-2019211379-0001:10000/spark;auth=noSasl")
19 .option("user","root")
20 .option("fetchsize","2000")
21 .option("dbtable", "spark.wordcount")
22 .load()
23 df.show(10)
24
25 val lines:RDD[String]=df.rdd.map((row: Row) => {row.get(0).toString})
26 val words:RDD[String]=lines.flatMap((line:String)=>line.split(" "))
27 val wordAndOne:RDD[(String,Int)]=words.map((word:String)=>(word,1))
28 val wordAndNum:RDD[(String,Int)]=wordAndOne.reduceByKey((x:Int,y:Int)=>x+y)
29 val ret=wordAndNum.sortBy(kv=>kv._2,false)
30 print(ret.collect().mkString(","))
31 ret.saveAsTextFile("hdfs://zzj-2019211379-0001:8020/spark/result")
32 spark.stop()
33 }
34
35 def register(): Unit = {
36 JdbcDialects.registerDialect(HiveSqlDialect)
37 }
38
39 case object HiveSqlDialect extends JdbcDialect {
40 override def canHandle(url: String): Boolean = url.startsWith("jdbc:hive2")
41
42 override def quoteIdentifier(colName: String): String = {
43 colName.split('.').map(part => s"`$part`").mkString(".")
44 }
45 }
46}
打包,删除 MANIFEST.MF,上传:
scp "C:\Repo\big-data\spark-test\spark-test\out\artifacts\spark_test_jar\spark-test.jar" root@zzj-2019211379-0001:~
提交
spark-submit --master yarn --num-executors 3 --driver-memory 1g --executor-memory 1g --executor-cores 1 --class org.example.ScalaWordCount spark-test.jar
hdfs dfs -ls /spark/result

导出
hdfs dfs -get /spark/result/part-00000 /root
最终结果:

参考资料
Setting Up the Database for the Hive Metastore - Hortonworks Data Platform (cloudera.com)