阅读大规模代码:挑战与实践(4)深入代码细节
深入代码细节
在掌握了代码的宏观结构,尤其是模块关系和核心概念之后,我们终于开始面对最头疼和耗时的部分——深入细节。本章将介绍几种有效的方法,帮助你分析代码,掌握其内部运作机制。
本章最关键,最有用的知识就是学会反向阅读代码,达到事倍功半的效果!
警告:阅读代码细节,虽然字面上要“细”,但并不是真的要流水账般咀嚼每一行。我们基本上要遵循以下原则:
应该是什么样的:
-
理解功能和架构,以便优化、修复或扩展。
-
理解逻辑,从中学习编程思想、风格和最佳实践。
-
按照逻辑链路而非编译器解析链路来理解代码。
-
关注代码的美感和算法的巧妙实现,通过翻阅历史版本简化理解难度。
不应该是什么样的:
-
被动阅读代码,追求细节的理解,而不去理解其功能和架构。
-
总是接受作者的写法,不思考其实别人的写法(哪怕是知名程序员)其实也并不总是好的。
-
尝试逐函数、逐行理解,没有跳跃性。
-
死磕复杂、冗长和难懂的代码,而不去思考其核心逻辑(有可能算法本身简单,只是日积月累已经是屎山,而你却硬啃屎山)。
空话说完,我们必须决定从哪里入手了。
阅读测试代码
测试代码提供了对被测试代码预期行为的直接洞察。测试有很多种,一般可以分成集成测试和单元测试。集成测试关注模块之间的接口和交互的正确性。单元测试关注于单个模块的功能正确性。这恰好对应了代码的整体理解和局部理解。通过阅读单元测试,你可以了解函数或模块的使用方式、处理的输入输出以及边界条件。而集成测试则可以帮助你了解模块之间连接关系。二者结合可以得到比较全面的理解。所以从测试开始是最好的方法。
让我们以下面的 LLVM 某个单元测试代码为例。(你不需要事先对 LLVM 有所了解)
1TEST(UseTest, sort) {
2 LLVMContext C;
3
4 const char *ModuleString = "define void @f(i32 %x) {\n"
5 "entry:\n"
6 " %v0 = add i32 %x, 0\n"
7 " %v2 = add i32 %x, 2\n"
8 " %v5 = add i32 %x, 5\n"
9 " %v1 = add i32 %x, 1\n"
10 " %v3 = add i32 %x, 3\n"
11 " %v7 = add i32 %x, 7\n"
12 " %v6 = add i32 %x, 6\n"
13 " %v4 = add i32 %x, 4\n"
14 " ret void\n"
15 "}\n";
16 SMDiagnostic Err;
17 char vnbuf[8];
18 std::unique_ptr<Module> M = parseAssemblyString(ModuleString, Err, C);
19 Function *F = M->getFunction("f");
20 ASSERT_TRUE(F);
21 ASSERT_TRUE(F->arg_begin() != F->arg_end());
22 Argument &X = *F->arg_begin();
23 ASSERT_EQ("x", X.getName());
24
25 X.sortUseList([](const Use &L, const Use &R) {
26 return L.getUser()->getName() < R.getUser()->getName();
27 });
28 unsigned I = 0;
29 for (User *U : X.users()) {
30 format("v%u", I++).snprint(vnbuf, sizeof(vnbuf));
31 EXPECT_EQ(vnbuf, U->getName());
32 }
33 ASSERT_EQ(8u, I);
34
35 X.sortUseList([](const Use &L, const Use &R) {
36 return L.getUser()->getName() > R.getUser()->getName();
37 });
38 I = 0;
39 for (User *U : X.users()) {
40 format("v%u", (7 - I++)).snprint(vnbuf, sizeof(vnbuf));
41 EXPECT_EQ(vnbuf, U->getName());
42 }
43 ASSERT_EQ(8u, I);
44}
首先,我们看到这是一个测试函数 UseTest.sort。这个测试用例的目的是检验 LLVM 中 Use 列表的排序功能。
1. 创建 LLVM 上下文和模块
1LLVMContext C;
2const char *ModuleString = "define void @f(i32 %x) {...}";
3SMDiagnostic Err;
4std::unique_ptr<Module> M = parseAssemblyString(ModuleString, Err, C);
-
LLVMContext: 这是 LLVM 的一个核心类,用于管理编译过程中的全局数据,比如类型和常量。通过上下文,我们能确保多线程环境下的数据安全。
-
Module: 代表一个 LLVM 模块,是 LLVM IR 中的顶级容器,包含函数和全局变量等。
-
parseAssemblyString: 这个函数将 LLVM IR 字符串解析为一个模块对象。我们在这里了解到 LLVM 提供了丰富的 API 来处理和操作 IR。
这几行代码让我们意识到,对一个模块源码进行解析,得到一个关联到上下文的模块对象。这让我们对 LLVM 的模块组织有了一个印象。
2. 获取函数和参数
1Function *F = M->getFunction("f");
2ASSERT_TRUE(F);
3ASSERT_TRUE(F->arg_begin() != F->arg_end());
4Argument &X = *F->arg_begin();
5ASSERT_EQ("x", X.getName());
这些代码意味着 LLVM IR 中 define void @f(i32 %x) 表示一个函数 f,其参数名为 x。并且我们学到了可以通过 *F->arg_begin() 获取函数的第一个参数。这看起来像个迭代器,推测可以遍历函数的所有参数。我们还学到了可以通过 getName() 方法获取参数的名称。
而这事先不需要你对 LLVM IR 有所了解。
3. 使用列表排序
1X.sortUseList([](const Use &L, const Use &R) {
2 return L.getUser()->getName() < R.getUser()->getName();
3});
这里显然定义排序规则,根据 User 的 Name 进行排序。
4. 验证排序结果
1unsigned I = 0;
2for (User *U : X.users()) {
3 format("v%u", I++).snprint(vnbuf, sizeof(vnbuf));
4 EXPECT_EQ(vnbuf, U->getName());
5}
6ASSERT_EQ(8u, I);
这里我们学到的是可以通过 users() 方法获取 Use 列表,并遍历它。根据断言,我们得到的顺序是 v0 到 v7。
结合 X 的定义,我们推测 Use 表示哪些“users”用到了 x。
实际上这是编译原理的 Use-Def 分析的一部分,虽然我们不懂编译原理,但我们通过阅读测试代码开始有点了解了!
5. 逆序排序
1X.sortUseList([](const Use &L, const Use &R) {
2 return L.getUser()->getName() > R.getUser()->getName();
3});
- 这部分代码用相反的排序规则对
Use列表进行逆序排列。略。
小结一下,这里我们仅仅通过测试,就开始有点理解一门新语言 LLVM IR,还对编译中的 Use 关系有了一定的了解。这可比去读 LLVM IR Parser 或者编译原理的书来的快多了!(当然,如果你真的要从事这方面的工作,还是需要去啃的)
函数分析:追踪输入变量的来源
现在祭出一个能大大提高阅读效率的方法——变量来源分析。
1impl SelfTime {
2 ...
3 pub fn self_duration(&mut self, self_range: Range<Duration>) -> Duration {
4 if self.child_ranges.is_empty() {
5 return self_range.end - self_range.start;
6 }
7
8 // by sorting child ranges by their start time,
9 // we make sure that no child will start before the last one we visited.
10 self.child_ranges
11 .sort_by(|left, right| left.start.cmp(&right.start).then(left.end.cmp(&right.end)));
12 // self duration computed by adding all the segments where the span is not executing a child
13 let mut self_duration = Duration::from_nanos(0);
14
15 // last point in time where we are certain that this span was not executing a child.
16 let mut committed_point = self_range.start;
17
18 for child_range in &self.child_ranges {
19 if child_range.start > committed_point {
20 // we add to the self duration the point between the end of the latest span and the beginning of the next span
21 self_duration += child_range.start - committed_point;
22 }
23 if committed_point < child_range.end {
24 // then we set ourselves to the end of the latest span
25 committed_point = child_range.end;
26 }
27 }
28
29 self_duration
30 }
31}
摘自:https://github.com/meilisearch/meilisearch/blob/main/crates/tracing-trace/src/processor/span_stats.rs
看见这一大坨代码不要慌,先看函数签名 fn self_duration(&mut self, self_range: Range<Duration>) -> Duration,这说明输入一个 Duration,输出也是 Duration,而且函数可能会修改当前对象的状态。
然后我们直接跳到返回值 self_duration 双击选中,看到其实修改它的就一处 self_duration += child_range.start - committed_point;
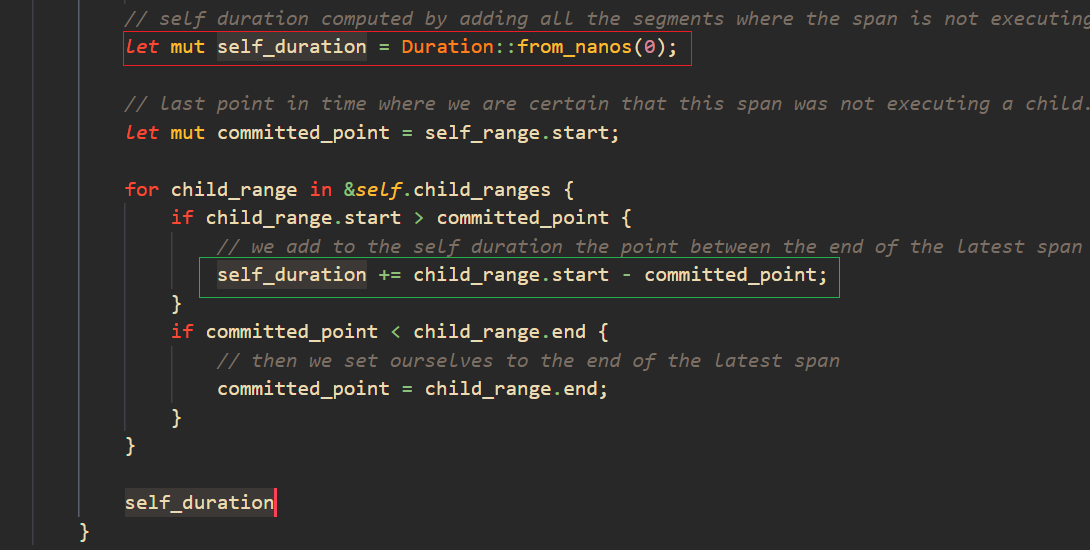
此时就知道它其实就是把一系列的区间长度求和,区间的开始为 child_range.start,区间的结束为 committed_point。
然后我们对 committed_point 还是不了解,再双击选中 committed_point。
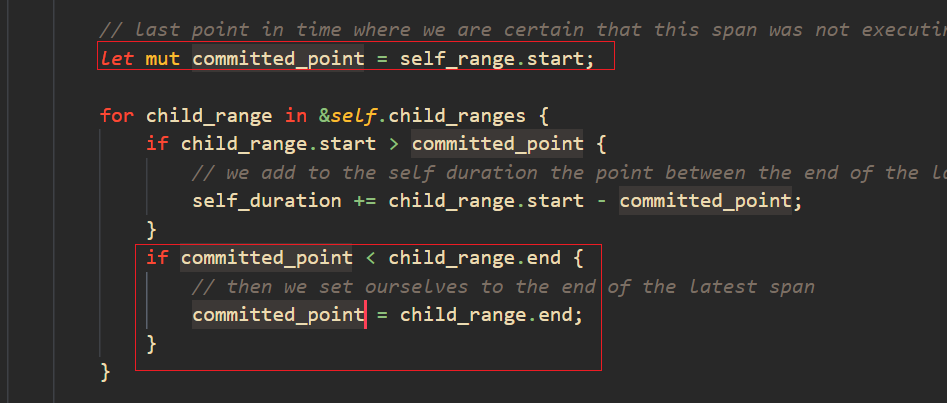
发现对它的修改也只有一处,就是当 committed_point < child_range.end 时,committed_point 被设置为 child_range.end。
两相结合就是说 self_duration 其实就是本次的 child_range.start 剪掉上次 committed_point 之间的长度。也就是说反映了 child_range 与 committed_point 之间没有执行的区间(空隙)长度。
所以整体代码的意思就是:
-
先对 child_ranges 进行排序,保证 child_range.start 都小于等于前一个 child_range.end。
-
然后遍历 child_ranges,将其间的空隙累加到 self_duration,并更新 committed_point。committed_point 表示上次 child_range 的末尾。
-
最后返回 self_duration。
再看开头的条件,就是说如果 child_ranges 为空,那么 self_duration 就是 self_range.end - self_range.start。即没有子区间,则空隙就是整个区间。
总结一下:来源分析的方法,就是从后往前分析变量的生成和传递路径,从而理解变量的来源。这比你顺着读要好读很多,因为越靠前的语句,越有可能只是用来凑参数的!实际上我们平时写代码也是这样,代码的核心语句就一两条,此上很多条都是为了给这几个核心语句计算参数。
过程块理解
理解代码中的过程块(如条件块、函数块等)关键在于删繁就简。
排除Guard语句,找到核心逻辑
Guard 语句通常用于提前退出函数或处理异常情况。排除这些语句,可以让你更专注于函数的主要逻辑。这种代码在业务代码中尤其常见。
下面摘自:https://github.com/kubernetes/kubernetes/blob/master/pkg/registry/core/pod/strategy.go
1// ResourceLocation returns a URL to which one can send traffic for the specified pod.
2func ResourceLocation(ctx context.Context, getter ResourceGetter, rt http.RoundTripper, id string) (*url.URL, http.RoundTripper, error) {
3 // Allow ID as "podname" or "podname:port" or "scheme:podname:port".
4 // If port is not specified, try to use the first defined port on the pod.
5 scheme, name, port, valid := utilnet.SplitSchemeNamePort(id)
6 if !valid {
7 return nil, nil, errors.NewBadRequest(fmt.Sprintf("invalid pod request %q", id))
8 }
9
10 pod, err := getPod(ctx, getter, name)
11 if err != nil {
12 return nil, nil, err
13 }
14
15 // Try to figure out a port.
16 if port == "" {
17 for i := range pod.Spec.Containers {
18 if len(pod.Spec.Containers[i].Ports) > 0 {
19 port = fmt.Sprintf("%d", pod.Spec.Containers[i].Ports[0].ContainerPort)
20 break
21 }
22 }
23 }
24 podIP := getPodIP(pod)
25 if ip := netutils.ParseIPSloppy(podIP); ip == nil || !ip.IsGlobalUnicast() {
26 return nil, nil, errors.NewBadRequest("address not allowed")
27 }
28
29 loc := &url.URL{
30 Scheme: scheme,
31 }
32 if port == "" {
33 // when using an ipv6 IP as a hostname in a URL, it must be wrapped in [...]
34 // net.JoinHostPort does this for you.
35 if strings.Contains(podIP, ":") {
36 loc.Host = "[" + podIP + "]"
37 } else {
38 loc.Host = podIP
39 }
40 } else {
41 loc.Host = net.JoinHostPort(podIP, port)
42 }
43 return loc, rt, nil
44}
这里很多语句都是验证参数之类的,删掉之后变成这样(port 为空的逻辑,一定程度上也可以看做 edge case,虽然对程序正确性至关重要,但是阅读的时候瞟一眼就行):
1// ResourceLocation returns a URL to which one can send traffic for the specified pod.
2func ResourceLocation(ctx context.Context, getter ResourceGetter, rt http.RoundTripper, id string) (*url.URL, http.RoundTripper, error) {
3 // Allow ID as "podname" or "podname:port" or "scheme:podname:port".
4 // If port is not specified, try to use the first defined port on the pod.
5 scheme, name, port, _ := utilnet.SplitSchemeNamePort(id)
6 pod, _ := getPod(ctx, getter, name)
7 podIP := getPodIP(pod)
8 loc := &url.URL{
9 Scheme: scheme,
10 }
11 loc.Host = net.JoinHostPort(podIP, port)
12 return loc, rt, nil
13}
是不是感觉一下子代码变得慈眉善目了?严格来说这个代码的核心逻辑就两句话:
-
通过
utilnet.SplitSchemeNamePort解析不同部分。 -
构造一个 URL 对象,并设置 Host 字段。
利用命名猜测功能
良好的命名可以提供大量信息,结合上下文,能帮助你快速理解代码的功能和目的。通过分析变量、函数和类的命名,可以推测其作用和关联。
不良好的命名,咱也可以先大胆猜测。下面的代码摘自 https://github.com/nodejs/node/blob/main/src/large_pages/node_large_page.cc
1struct text_region FindNodeTextRegion() {
2 struct text_region nregion;
3#if defined(__linux__) || defined(__FreeBSD__)
4 dl_iterate_params dl_params;
5 uintptr_t lpstub_start = reinterpret_cast<uintptr_t>(&__start_lpstub);
6
7#if defined(__FreeBSD__)
8 // On FreeBSD we need the name of the binary, because `dl_iterate_phdr` does
9 // not pass in an empty string as the `dlpi_name` of the binary but rather its
10 // absolute path.
11 {
12 char selfexe[PATH_MAX];
13 size_t count = sizeof(selfexe);
14 if (uv_exepath(selfexe, &count))
15 return nregion;
16 dl_params.exename = std::string(selfexe, count);
17 }
18#endif // defined(__FreeBSD__)
19
20 if (dl_iterate_phdr(FindMapping, &dl_params) == 1) {
21 Debug("start: %p - sym: %p - end: %p\n",
22 reinterpret_cast<void*>(dl_params.start),
23 reinterpret_cast<void*>(dl_params.reference_sym),
24 reinterpret_cast<void*>(dl_params.end));
25
26 dl_params.start = dl_params.reference_sym;
27 if (lpstub_start > dl_params.start && lpstub_start <= dl_params.end) {
28 Debug("Trimming end for lpstub: %p\n",
29 reinterpret_cast<void*>(lpstub_start));
30 dl_params.end = lpstub_start;
31 }
32
33 if (dl_params.start < dl_params.end) {
34 char* from = reinterpret_cast<char*>(hugepage_align_up(dl_params.start));
35 char* to = reinterpret_cast<char*>(hugepage_align_down(dl_params.end));
36 Debug("Aligned range is %p - %p\n", from, to);
37 if (from < to) {
38 size_t pagecount = (to - from) / hps;
39 if (pagecount > 0) {
40 nregion.found_text_region = true;
41 nregion.from = from;
42 nregion.to = to;
43 }
44 }
45 }
46 }
47#elif defined(__APPLE__)
48 struct vm_region_submap_info_64 map;
49 mach_msg_type_number_t count = VM_REGION_SUBMAP_INFO_COUNT_64;
50 vm_address_t addr = 0UL;
51 vm_size_t size = 0;
52 natural_t depth = 1;
53
54 while (true) {
55 if (vm_region_recurse_64(mach_task_self(), &addr, &size, &depth,
56 reinterpret_cast<vm_region_info_64_t>(&map),
57 &count) != KERN_SUCCESS) {
58 break;
59 }
60
61 if (map.is_submap) {
62 depth++;
63 } else {
64 char* start = reinterpret_cast<char*>(hugepage_align_up(addr));
65 char* end = reinterpret_cast<char*>(hugepage_align_down(addr+size));
66
67 if (end > start && (map.protection & VM_PROT_READ) != 0 &&
68 (map.protection & VM_PROT_EXECUTE) != 0) {
69 nregion.found_text_region = true;
70 nregion.from = start;
71 nregion.to = end;
72 break;
73 }
74
75 addr += size;
76 size = 0;
77 }
78 }
79#endif
80 Debug("Found %d huge pages\n", (nregion.to - nregion.from) / hps);
81 return nregion;
82}
我们先把非核心代码删掉,把某些逻辑块替换成伪代码:
1struct text_region FindNodeTextRegion() {
2 struct text_region nregion;
3 dl_iterate_params dl_params;
4 uintptr_t lpstub_start = reinterpret_cast<uintptr_t>(&__start_lpstub);
5
6 if (dl_iterate_phdr(FindMapping, &dl_params) == 1) {
7 dl_params.start = dl_params.reference_sym;
8 if (lpstub_start > dl_params.start && lpstub_start <= dl_params.end) {
9 dl_params.end = lpstub_start;
10 }
11
12 if (dl_params.start < dl_params.end) {
13 char* from = hugepage_align_up(dl_params.start);
14 char* to = hugepage_align_down(dl_params.end);
15 Debug("Aligned range is %p - %p\n", from, to);
16 if (from < to) {
17 size_t pagecount = (to - from) / hps;
18 if (pagecount > 0) {
19 Set nregion data;
20 }
21 }
22 }
23 }
24 return nregion;
25}
删繁就简之后,我们直接定位 nregion 的赋值点,找到了核心逻辑:寻找一个 hugepage 区域。
dl_iterate_phdr 这个函数虽然事先不知道什么意思,但是从名字来看有迭代,意味着其内部会循环地执行,从使用来看,返回 == 1 应该是表示找到了东西。而参数 FindMapping 应该是表示查找的回调函数。因此我们推测 dl_iterate_phdr 的功能应该是遍历进程的一些操作系统管理的数据,找到其中满足 FindMapping 条件的,把结果放到 dl_params。
实际上 dl 是动态链接(dynamic linking)的缩写。phdr: 程序头(program header)的缩写。所以整个函数就是遍历当前进程加载的所有程序头(包括程序和库)的函数。不同领域会有不同的缩写,
比如:
-
irq: Interrupt Request
-
pcb: Process Control Block
-
mmu: Memory Management Unit
-
dma: Direct Memory Access
-
vfs: Virtual File System
-
ipc: Inter-Process Communication
-
pid: Process Identifier
-
tss: Task State Segment
-
smp: Symmetric Multiprocessing
-
numa: Non-Uniform Memory Access
熟悉之后可以帮助我们快速理解代码,避免频繁查文档,递归式查各种文档耽误时间。