Microsoft Bing 大数据 Gateway 维护笔记
概述
本文总结了维护和重构 BingViz Gateway,最后历经高流量、高并发的实际检验,实现稳定可靠服务的过程。
何为 Gateway
在我们提供的大数据基础服务中,Gateway 是埋点数据的提交入口,是一个作为消息中继的微服务,采用 NodeJS 语言编写。
其初始结构图如下(后期进行了大刀阔斧的改进,详见后文):

可以看到,Gateway 上乘 Azure Frontdoor,下启 Azure Eventhub。
-
Frontdoor 是 Azure 提供的 CDN,直接来自用户端(如移动 App、PC 软件)的请求,并进行基础的分流和 WAF 安全检查,并将通过的流量转发给不同对接了不同 Eventhub 的 Gateway.
-
Gateway 负责更细致和灵活的请求校验,并转发至 Eventhub。Gateway 约有四五十个,分属四个 Eventhub(分别对应四类主要来源)。Frontdoor 虽然也有过滤功能,为了确保效率,同时受其设计所限,灵活性差,是不会对请求体进行复杂的解析和检查的。这一重担交由 Gateway 完成,灵活性体现在:
-
利用代码实现了复杂的过滤规则:对不规范的请求进行纠错,对无效的请求丢弃
-
可以动态地从 PGSQL 拉取 Application List 从而确保用户提交的数据所属 App 是合法的
-
-
Eventhub 是 Azure 提供的高性能消息队列。消息被送入其中之后,会进一步流向之后的 ELK 和 DataLake。
部署数量:大概部署了 50 个 Service,每个 Service 有 2~3 个 Instance 作为热备(每个 Instance 拥有独立的内存与计算单元)。使用 Azure 的 App Service 部署,你可以理解为一个 Docker 容器。使用 Azure DevOps Release Pipeline 自动部署。
业务流量:在优化之前,Gateway 的日常流量为 300M。截至目前,每日请求总量大概 600M,已逐渐回归正常。最高峰曾经在 1.2M 左右。
整体而言,流量的最高峰出现在 2022/3/28 3:00:43 (北京时间),其 15 分钟请求总量为 21.4M,即 23766 QPS。
单服务业务峰值出现在 2022/3/29 8:00:43,服务结点为 bingviz-gw-v2-northcentralus-eh01-01,其 15 分钟请求总量为 1.79M,即 1989QPS,当时所有结点 5xx 错误率均为 0。这是经过无数个紧急代码更新升级之后的效果。对于以 POST 请求为主导的服务,取得如此效果,已属不易。
Live Site 事件特征概览
下图为 3 月 3 日至 4 月 3 日途径 Gateway 的请求总数。可以看到,正常情况的请求不超过 300M/Day,自 3 月 13 日起,由于 LiveSite 事件,请求量逐日而升,有指数增长之意。在大家齐心协力之下,3 月 29 日左右终于产生了回归正常的趋势,在近日已逐渐靠近异常增长之前的水平。
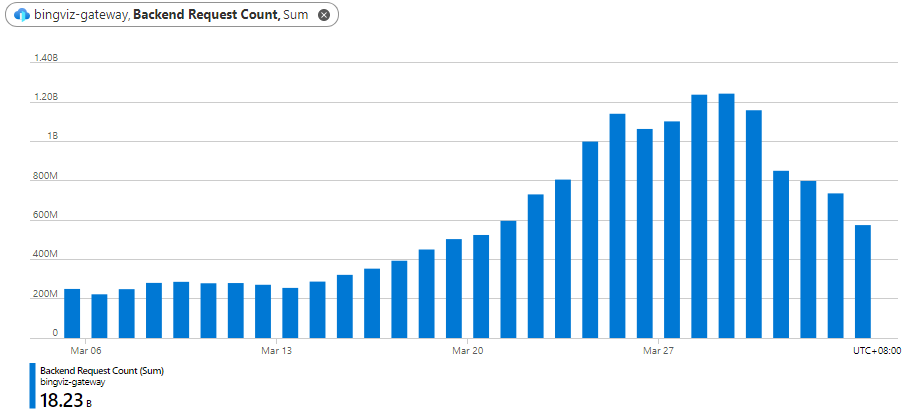
Gateway 服务在此事件中的演进
上图可以关注 13~29 日流量的急速增长期。可与之参照的是 5XX 错误率,反应了 Service 是否正常工作。如下图所示:
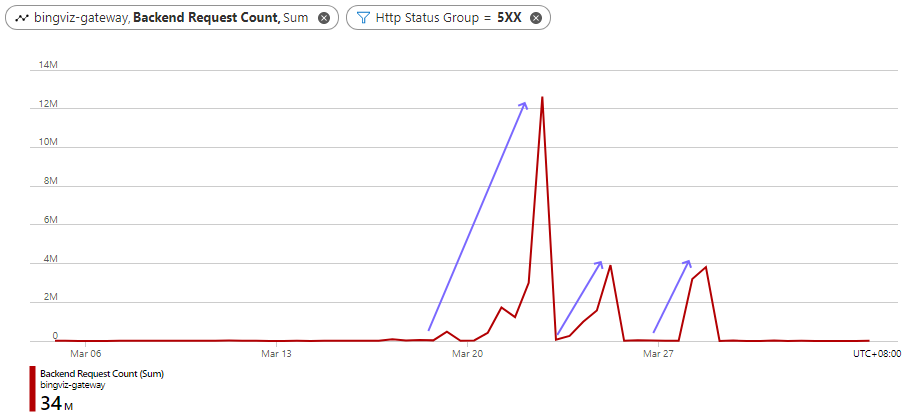
可以看到,随着 13~29 日流量的急速增长,5XX 错误率经历了 3 个上升阶段(分别为:22 日 21:00,25 日 9:00,28 日 15:00)。每一个阶段,经过代码优化和架构优化之后,在承受相比之前更高流量的同时,错误率都得到了有效的遏制。这三个阶段分别对应了 Gateway 及其下游设施的的三个关键重构:
(1)第一个错误率高峰的消灭:稳定性综合优化。在此次危机出现之前,我们就已经在执行计划中的 Gateway 改进,从而大大减小了本次危机的损失,增加了更多的应对空间。主要是:
-
**平台的迁移。**代码仓库的迁移。服务平台的迁移:从 Windows Server 迁移到 Linux。DevOps 相关迁移:将相关部署流水线迁移到新的仓库。将依赖特定的 Deploy Agent 更改为使用通用 Ubuntu Agent,从而避免了排队,可以快速并行部署上限一批服务。
-
**日志系统的对接。**将阻塞的默认 Console 日志更改为高性能日志库,在代码关键位置设置不同 Level 的日志埋点。将新的 App Service 接入到统一的日志分析中心。
新的 Service 以试点的方式追加到了 EH03 后端池中,并分入了少量的流量。就此我们得以分析线上的日志,并送入日志中心。很快,我们就立刻在其中发现了大量的隐患问题,后来又将 EH04 的少量流量分入,又进一步发现了更隐蔽的问题。主要包括:
-
PGSQL 连接错误导致崩溃。此问题通过增加错误监听解决。
-
**SOCKET 事件监听器数量超限。**此问题造成内存泄漏,经查是 restify 框架的逻辑 bug 导致资源未释放。升级依赖后解决。
-
Eventhub 连接失败问题。此问题造成 Events 丢失而不知。后面我们在第一次大更新中加入一次重传机制,在之后的一次更新中加入三次重传机制。问题得到大部分解决。
-
EROFS: read-only file system. 此问题造成服务崩溃。后面我们加了 Try-Catch 并引入互斥锁避免并发写,基本解决。
我们从日志发现,5xx 错误大量产生几乎都是因为服务器崩溃重启导致的。经过第一次大的更新,能够基本保障 Gateway 不崩溃,从而千万级别的 5xx 错误不复存在。
(2)第二个错误率高峰的消灭:Batch 窗口机制优化。
在 EH02~EH04 普遍换成新 Gateway 之后,发现仍然收集到不少值得重视的错误日志。典型的有:
1[EventHub] Error when forwarding message: MessagingError: [connection-1] Sender "bingviz-prim-one-6f4597fb-1ae9-4db0-8422-3e3f919f3ec4", cannot send the message right now. Please try later., count = 11
1{"level":50,"time":1648439282299,"pid":48,"hostname":"5fbe9a6c0dfe","node":{"name":"bingviz-gw-v2-eastus-eh04-01","host":"5fbe9a6c0dfe"},"slot":"production","version":"20220321","data":{"err":{"name":"MessagingError","retryable":true,"code":"SenderBusyError"}},"msg":"[EventHub] Error while sending","v":1}
这类错误我们称为 SenderBusyError,最初我们查询 Github 从某 issue 得知可以通过增加 ProducerClient 数量解决。于是引入了 ClientPool 机制,但效果不显著。
那么,暴涨的请求量,究竟发送了什么东西呢?我很快写了 Event Statistics 功能,统计一段时间(如 1 min)内各个 App 发送的各个 Event 的数量,基本确定问题在于 iOS。我们向他们通知之后,修复此问题的版本很快发版,压制了情况恶化的增长趋势。
基于请求过多的事实,我们决定采用 Batch 优化,避免频繁向 Eventhub 发送消息。并且,于 3 月 24 日下午,我们完成了 Batch 窗口优化,其原理是积攒小的 Events 达到窗口容量之后再一次性发送。在 EH03 测试之后,上线于业务最为繁忙的 EH02。
在上线之前,我们也做了压力测试,测试 Local -> Gateway -> Eventhub 的链路到达情况。
Python 发送:
Gateway 统计:
Kibana 统计:
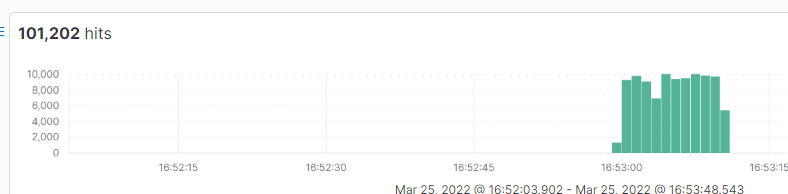
引入 Batch 机制的当天,就可以从 Eventhub 捕获消息量看到效果。在请求数暴增的同时,捕获消息量却打破这一增长趋势,稳在了 30~60M 区间。如下图所示,红色为引入 Batch 的时间点,洋红色为原先的增长趋势。
值得一提的是,随着每天优化后代码的部署,每个 Instance 的内存占用也顺带得到了优化。在部署时间点之后逐日下降。这说明说明吞吐率上来了,内存积压改善了。
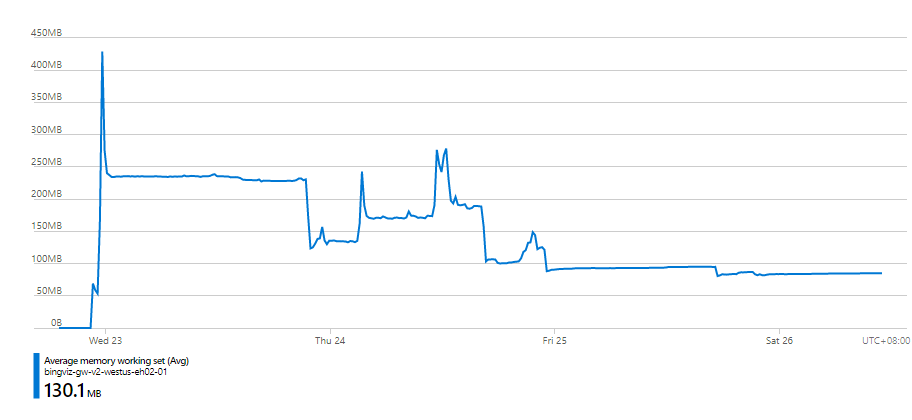
但是后来又出现了逆势增长,下面会说原因。
(3)第三个错误率高峰的消灭:下游 Eventhub 瓶颈的解决。
此阶段, Gateway 实际上已经不是瓶颈。对于 Gateway 自身,主要进行一些小修小补。
一是性能分析,发现 JSON 的解析和序列化占用了不少 CPU Burst,还有已经不再使用的 Application Insights 却依然消耗性能。并且请求大小判断放在了校验环节,万一遇到巨大的请求,将会直接导致服务器在 JSON 语法分析环节 CPU 飙满。对此我们在前置的中间件引入 Content-Length 限制,一旦请求体大小过于离奇,直接拒绝传输。
二是 PGSQL 的连接优化。发现可能出现查询超时排队,导致过多的异步任务同时请求,造成连接数耗尽的隐患。对其进行了修复。
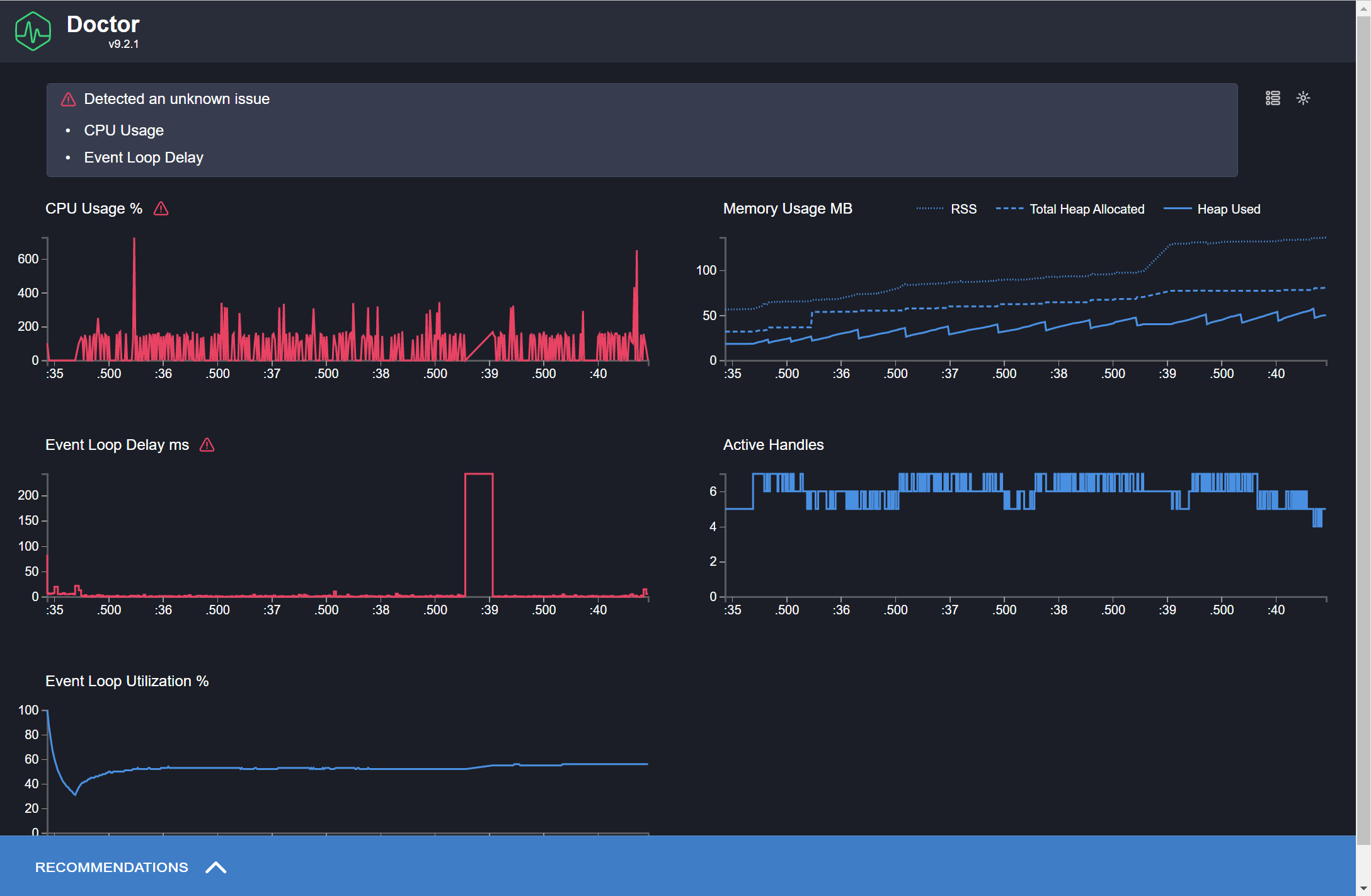
第三次 5xx 问题始末
更紧迫的事情在于,28 号,流量又一次水涨船高,同时,Gateway 出现百万级别 5xx 错误,以往这种情况必然是服务崩溃导致的,但无论看日志还是内存利用率变化,都没有崩溃的迹象。终于我们发现,Gateway 其实自身状态无异常,而是因为重试队列跑满导致报 503 的代码生效:
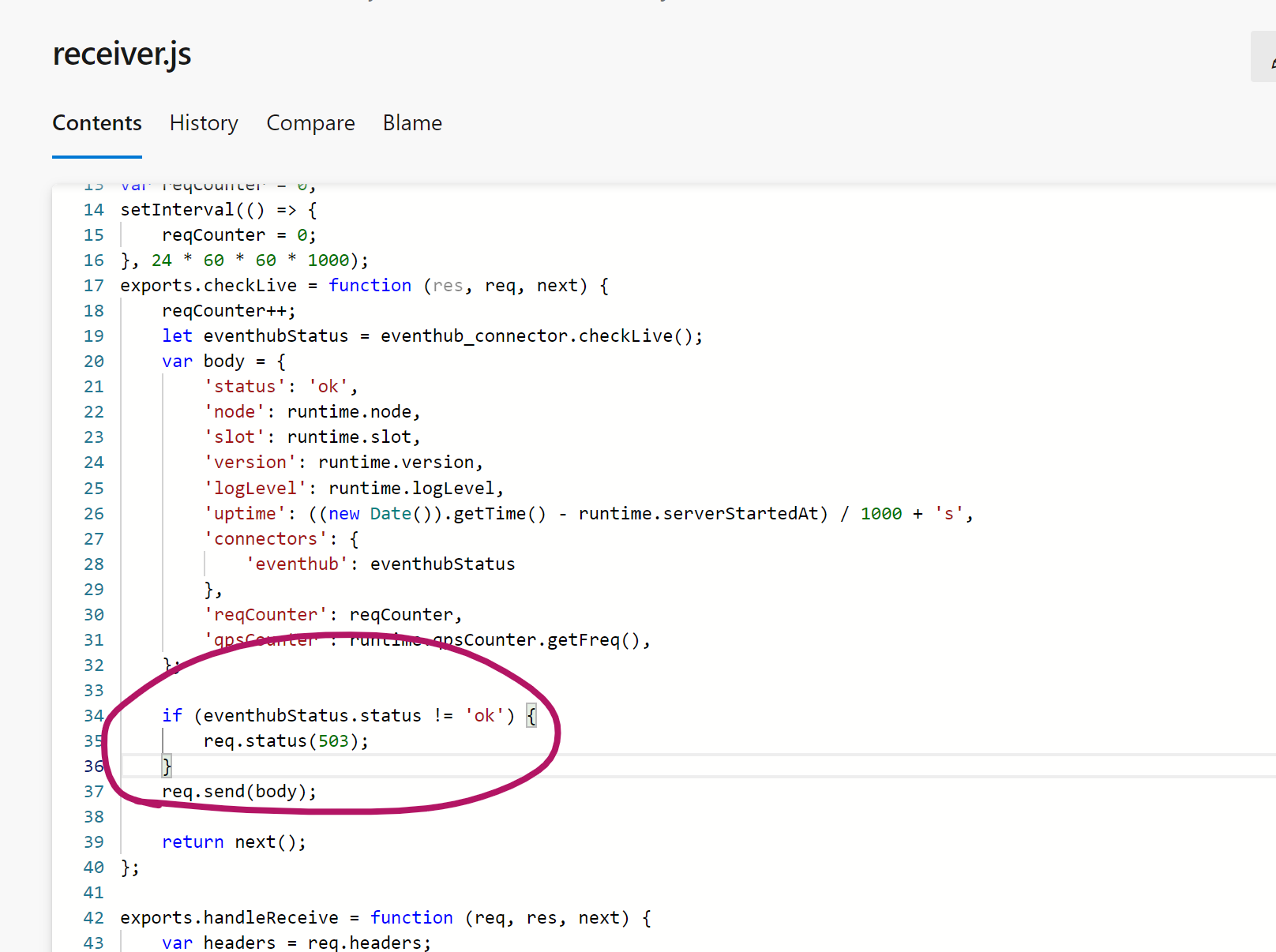
将这行代码删掉之后,5xx 错误归零,Gateway 自身的各项指标正常。
但根本问题是:为什么会有这么多重试中或是失败的消息?查看日志,主要是下面的错误:
-
[EventHub] Retry queue is full (max size is 500), message will be dropped. -
SenderBusyError -
ServerBusyException
ServerBusyException 是 Eventhub 自身的问题。深入研究并咨询专家之后,我们发现这是 Eventhub 的瓶颈,经过重建、架构优化,这一问题基本解决。
前文提到,SenderBusyError 通过 Batch 机制得到了解决,如今再次出现,令人不解。我们企图通过调整 EventhubProducerClient 数量参数以及 BatchSize 参数解决,未果。后来增加 Instance 数量之后,发现问题解决,我们推测是因为单个 Instance 即便进行了 Batch 优化,也只能往同一个 Eventhub Partition 写入,因此达到了单个 Partition 的瓶颈。因此,增加 Instance 数量可以平衡向各个 Parition 的写入。
总结以及新 Gateway 架构
至此,Gateway 的优化工作基本完成,各个问题基本解决,随着时间推移,请求量逐渐向正常靠近。
对于紧急增加了各种新功能的 Gateway,我们也在调整其架构,从而便于维护。目前的架构如下:

可以看到,基本的数据流未有改变。主要增加了如下功能:
-
预过滤。拒绝明显过大的请求,不再读其 Http Body,避免进入后续 JSON 解析环节浪费 CPU。
-
统计。包括 Requests,QPS 统计,Event 简单统计(成功、失败数)和精细统计(AppID 及其 Event 单位时间发送量)。这些指标有利于发生状况时快速定位原因,并且都有功能开关以及严格模式(加互斥锁)。
-
重试。可配置最大重试次数、重试间隔等。重试组件可开关。
-
合并发送。可使用池化的连接合并多个小的消息进行发送。可指定合并最高阈值,低于阈值的才合并。
-
消息追溯。可从 Kibana 中通过
gw字段追溯来源的 Gateway,出现异常及早发现。
改进了以下功能:
-
**缓存管理。**一是写缓存加锁,避免并发写导致崩溃。二是将缓存管理与具体数据源解耦。这样假定不再使用 PGSQL 提供 Application List,只需要重新实现 IApplistProvider。
-
**消息转发。**实现统一的 IMessageForwarder 接口,流水线设计模式,可以任意拼装实现更灵活的消息控制。