Transformer 和 BERT 模型介绍
发展脉络
NLP 领域的模型发展脉络如下:
-
Word2Vec
-
Transformer (T)
-
BERT
-
GPT
词义随上下文变化的问题
在不同的语境下,同一个词可能有不同的含义。如何处理这个问题是 NLP 领域的一个重要课题。
例如,在下面两个句子中,“it” 指代的对象是不同的:
-
The animal didn’t cross the street because it was too tired.
-
The animal didn’t cross the street because it was too wide.
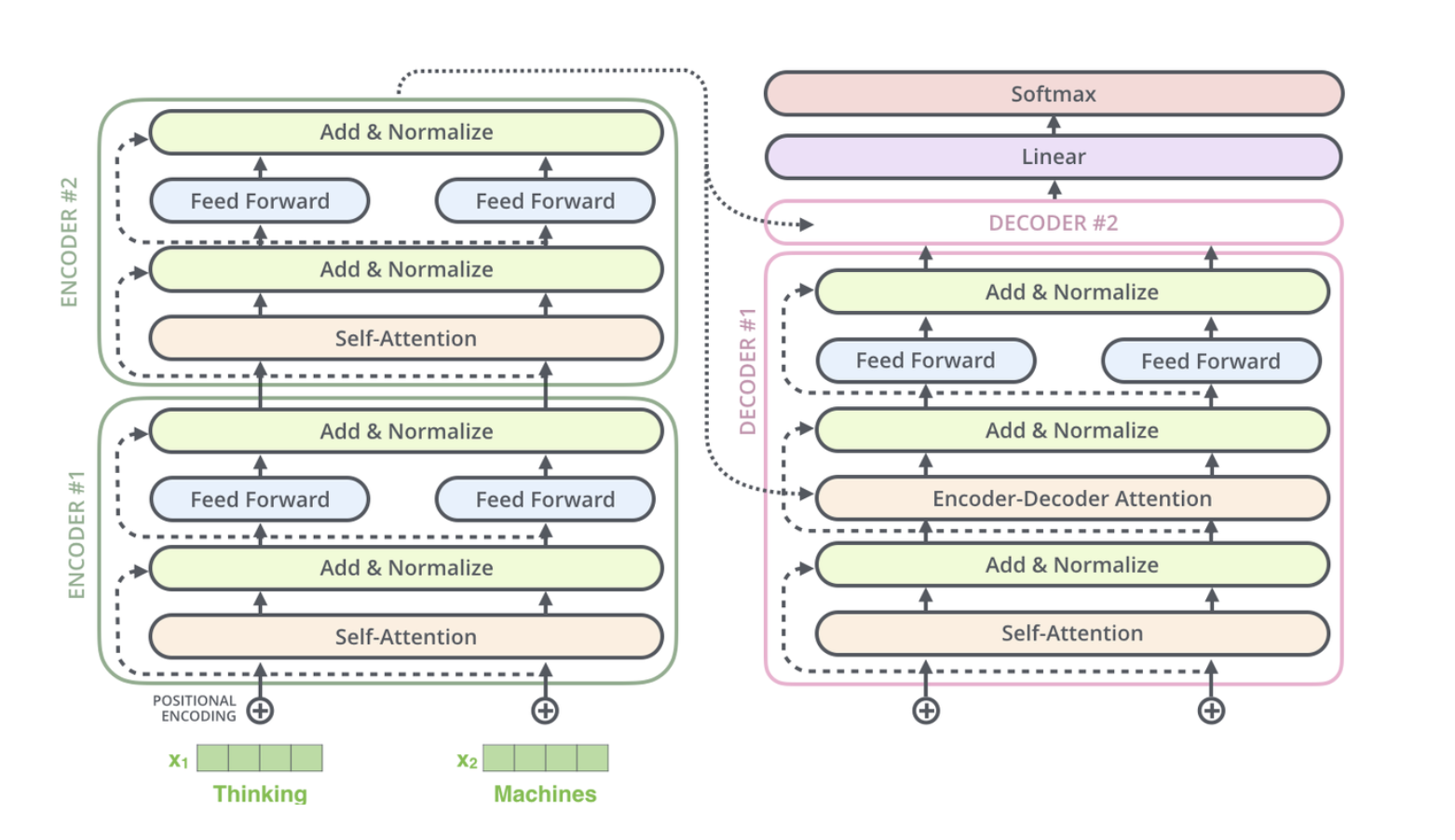
Transformer 编码器
Transformer 中最主要的计算单元是 Attention(注意力机制),即从一个样本中提取最重要的信息部分。

与 RNN 不同,RNN 中一个 token 只和周围的 token 有关系,而在 Transformer 中,我们是放眼全局的。
Self-Attention 的计算过程
以句子 “今天晚上吃河马” 为例,让 “今天” 这个词分别与 “今天”、“晚上”、“吃”、“河马” 计算权重,得到类似 0.5, 0.1, 0.3, 0.1 这样的权重值。
原来的词向量只考虑自己的特征,现在的词向量整合了其他词的特征,相当于有了上下文信息。整合前后的向量维度不变(假设均为 100 维),因为整合是加权求和的操作。这就是 Self-Attention:
-
输入:每个词的特征
-
输出:带有全局信息(其它词的影响)的每个词的特征
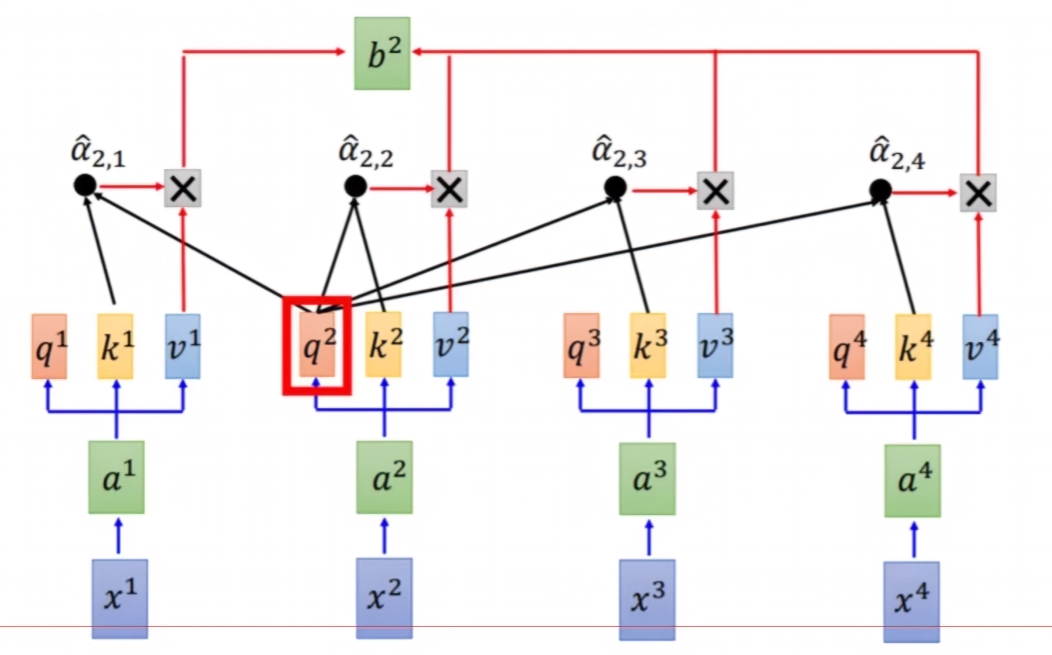
权重的计算方法

假设输入是两个词 $x_1$ 和 $x_2$,它们都是 4 维向量。对于 $x_1$,我们要查询它和其他词的关系。每个词都有两个向量:
-
Query 向量
$q$,用于查询 -
Key 向量
$k$,用于被查询
查询的结果向量称为:
- Value 向量
$v$
两个向量的内积(点积)越大,说明它们的相似度越高。因此,我们可以用内积来计算权重:
-
从
$x_1$出发,用$q_1$询问$k_1$:$q_1 \cdot k_1$,这表示$x_1$与自身的相似度,得到一个权重。 -
再用
$q_1$询问$k_2$:$q_1 \cdot k_2$,这表示$x_1$与$x_2$的相似度,得到另一个权重。 -
现在我们得到了两个标量权重值。
Query、Key、Value 向量的来源
$x_1$ 和 $x_2$ 是已知的输入,但 $q_1$, $q_2$, $k_1$, $k_2$ 等向量是如何得到的呢?
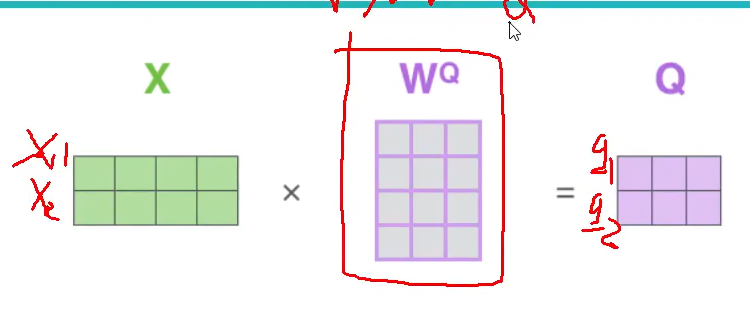
我们初始化权重矩阵 $W^Q$, $W^K$, $W^V$,分别表示从输入 $X$ 到 $Q$, $K$, $V$ 的线性变换。
$q_1$, $q_2$ 最初是随机初始化的,然后通过 $X$ 与 $W^Q$ 的乘积得到 $Q$:
$$
XW^Q=Q
$$
这实际上就是一个全连接层。同样地,我们可以得到 $K$ 和 $V$ 向量:
$$
XW^K=K
$$
$$
XW^V=V
$$
Transformer 的训练目标之一就是学习到合适的 $W^Q$, $W^K$, $W^V$ 权重矩阵,使得到的 $Q$, $K$, $V$ 向量能够很好地融合上下文信息,从而完成最终的任务。
为什么使用 Value 向量
在计算完权重后,我们用 Value 向量 $v_i$ 与权重 $w_i$ 相乘,得到 $\sum w_iv_i$,作为 $x_1$ 的一个表示,而不是直接用 $x_1$ 本身。
这是因为 $v_i$ 可以被看作是 $x_i$ 的一个"要点总结",它经过学习,能够体现 $x_i$ 的重要信息。所以用 $v_i$ 的加权求和来表示 $x_1$,比直接用 $x_1$ 更有代表性。
缩放点积注意力

对于 $Q \times K^\top$ 的结果,我们除以 $\sqrt{d_k}$($d_k$ 是 $K$ 的维度),并应用 Softmax 函数得到一个概率分布。
除以 $\sqrt{d_k}$ 的目的是对不同维度的数值进行归一化,类似于对不同科目的分数求平均。这种做法被称为缩放点积注意力(Scaled Dot-Product Attention)。
多头注意力(Multi-Head Attention)
从不同的"角度"看待同一个输入,然后将得到的多个表示进行拼接,这就是多头注意力机制。
拼接的优势在于,它可以得到更丰富的特征表示(因为维度变大了),而不同的"头"可以学习到不同的模式。
以上就是 Transformer 的 Encoder 部分,完成了特征提取的任务。
位置编码(Positional Encoding)
在上述的 Self-Attention 计算中,token 的出现位置对结果没有影响。但在很多情况下,词序是很重要的信息,如:
-
我吃河马
-
河马吃我
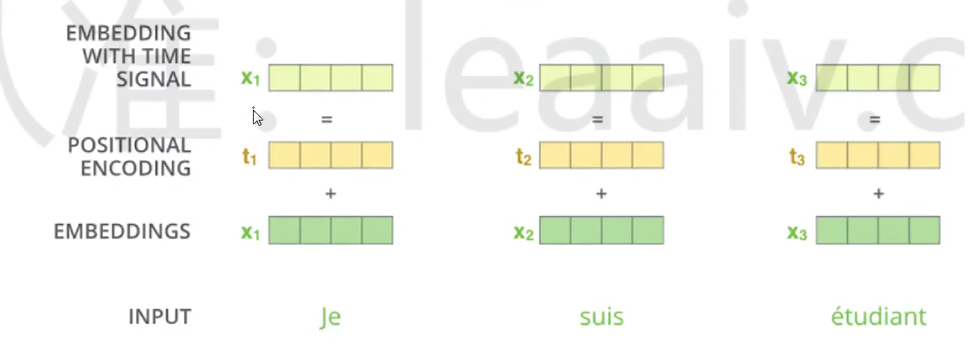
因此,在 Embedding 之后,我们加上位置编码,不同位置的词加上不同的位置编码,这样相同的词在不同位置的特征表示就不一样了。位置编码一般是固定的,不在训练过程中更新。
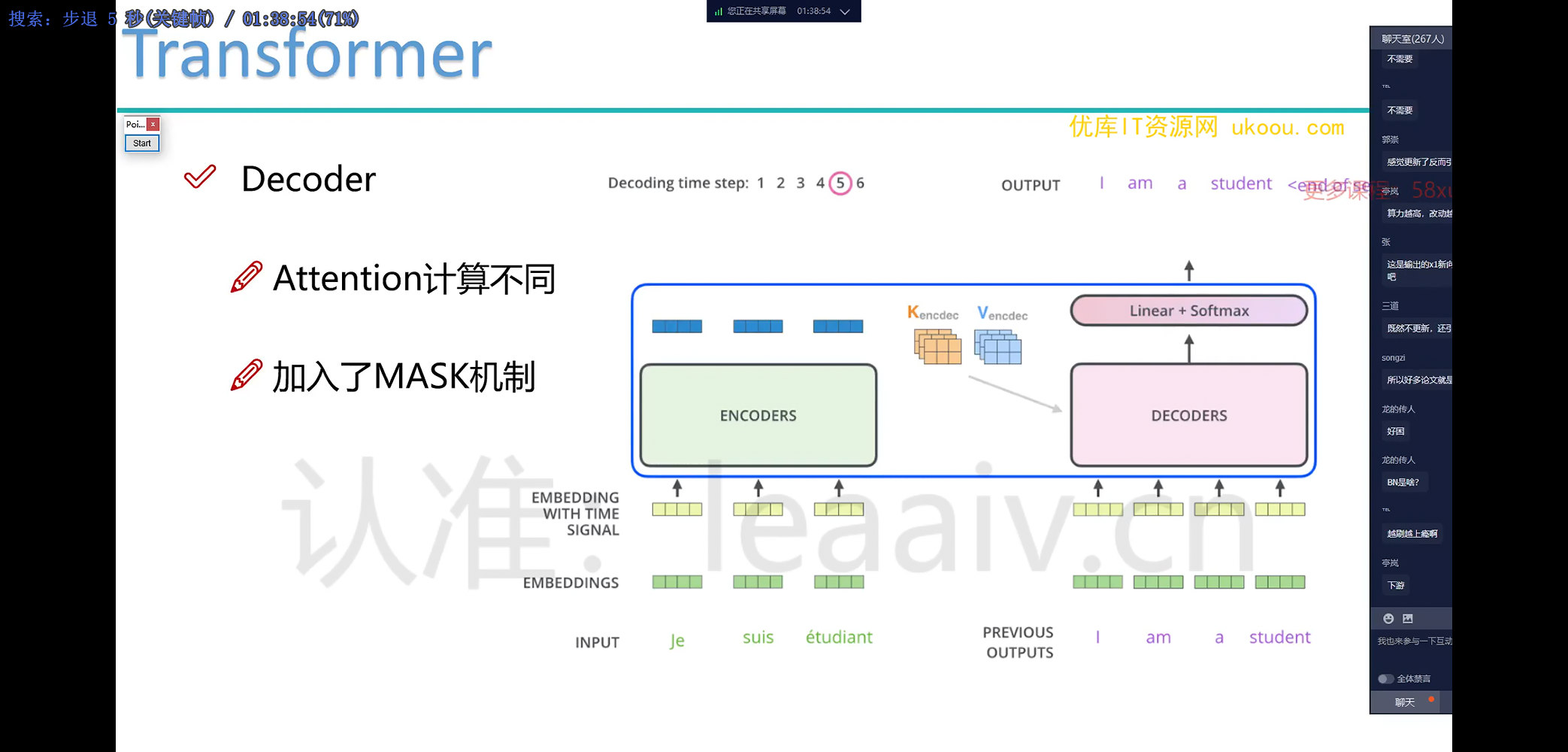
Transformer 的解码器
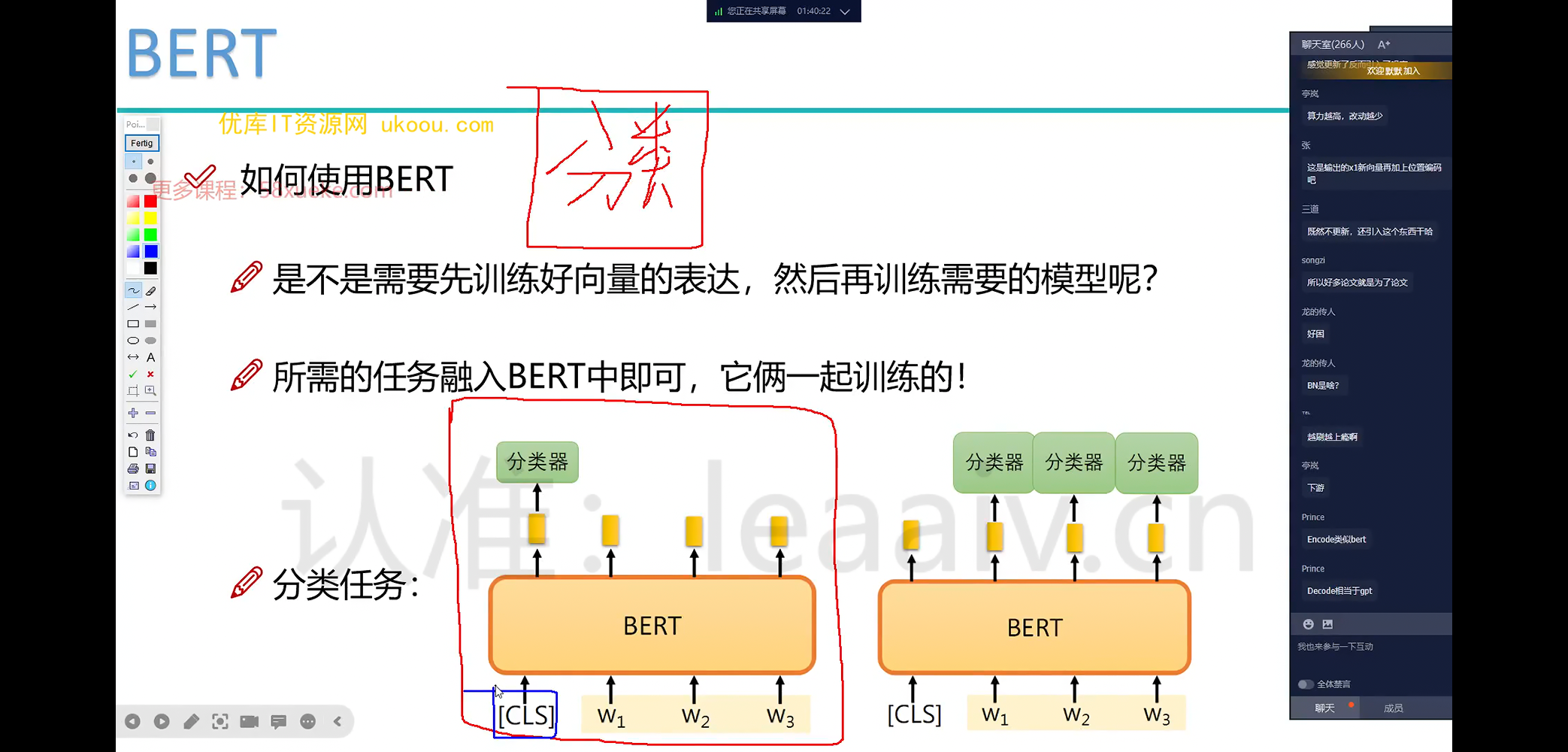
在 BERT 中,用一个特殊的 token [CLS] 表示分类任务。它也会参与到训练中,最后分类时使用 [CLS] 对应的输出向量进行计算。
在 Transformer 的 Decoder 中:
-
随机初始化第一个向量,让它与 Encoder 的输出向量进行 Cross Attention,将 Encoder 的信息整合到这个向量中,然后对这个词进行分类(预测这个词是什么)。
-
对于第二个词,除了与 Encoder 的输出进行 Cross Attention,还要与已经生成的第一个词进行 Self Attention。
Mask 机制
Mask 机制用于控制当前位置的词可以访问哪些位置的信息。比如在预测第二个词时,只允许访问前两个位置的信息,Mask 为 [1, 1, 0, 0, ...]。
BERT 的预训练方法
BERT 的一种预训练方法是 Masked Language Model(MLM):
随机 mask 掉句子中 15% 的词,然后让模型去预测这些被 mask 掉的词是什么。通过这种方式,BERT 可以学习到语言的通用表示。