HBase、ZooKeeper 集群部署及实践
ZooKeeper 集群部署
下载和解压
1wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
1scp "C:\Users\i\Downloads\Compressed\zookeeper-3.4.6.tar.gz" root@ecs-2019211379-0001:~
1mv zookeeper-3.4.6.tar.gz /usr/local/
2cd /usr/local/
3tar -zxvf zookeeper-3.4.6.tar.gz
4ln -s zookeeper-3.4.6 zookeeper
设置环境变量
1vi /etc/profile
1export ZOOKEEPER_HOME=/usr/local/zookeeper
2export PATH=$PATH:$ZOOKEEPER_HOME/bin
1. /etc/profile
配置节点
1cd /usr/local/zookeeper/conf
2cp zoo_sample.cfg zoo.cfg
3vi zoo.cfg
1dataDir=/usr/local/zookeeper/tmp
vim
cc可以清空当前行(不删除)
1server.1=ecs-2019211379-0001:2888:3888
2server.2=ecs-2019211379-0002:2888:3888
3server.3=ecs-2019211379-0003:2888:3888
4server.4=ecs-2019211379-0004:2888:3888
1mkdir /usr/local/zookeeper/tmp
2touch /usr/local/zookeeper/tmp/myid
复制到其它机器
此处如果带版本号传输,则后面需要手动建立符号链接
1scp -r /usr/local/zookeeper root@ecs-2019211379-0002:/usr/local
2scp -r /usr/local/zookeeper root@ecs-2019211379-0003:/usr/local
3scp -r /usr/local/zookeeper root@ecs-2019211379-0004:/usr/local
1scp /etc/profile root@ecs-2019211379-0002:/etc/profile
2scp /etc/profile root@ecs-2019211379-0003:/etc/profile
3scp /etc/profile root@ecs-2019211379-0004:/etc/profile
各机器 source /etc/profile
对于机器 $i:
1echo $i > /usr/local/zookeeper/tmp/myid
1
2mkdir /usr/local/zookeeper/tmp
3echo 1 > /usr/local/zookeeper/tmp/myid
4
5mkdir /usr/local/zookeeper/tmp
6echo 2 > /usr/local/zookeeper/tmp/myid
7
8mkdir /usr/local/zookeeper/tmp
9echo 3 > /usr/local/zookeeper/tmp/myid
10
11mkdir /usr/local/zookeeper/tmp
12echo 4 > /usr/local/zookeeper/tmp/myid
启动
各机器启动:
1cd /usr/local/zookeeper/bin
2./zkServer.sh start
查看状态:
1./zkServer.sh status若 Mode 为一个
leader,三个follower,则正确。 重启:1./zkServer.sh restart
遇到的问题
-
Mode: standalone 这是
zoo.cfg的 server 配置有误。检查配置项是否正确,本机 id 是否正确。 -
Error contacting service. It is probably not running. 先用
./zkServer.sh start-foreground启动,可以看到输出:ERROR [main:QuorumPeerMain@89] - Unexpected exception, exiting abnormally java.net.BindException: Address already in use因此
./zkServer.sh stop关闭,再启动,看到:Cannot open channel to 3 at election address ecs-2019211379-0003/192.168.0.203:3888 java.net.ConnectException: Connection refused (Connection refused)据此可知,DNS 无问题,问题在于网络无法互联。 修改各机器,让其自己的编号的地址设为 0.0.0.0,即可公网监听:

正确状态:


HBase 的部署
下载
wget https://archive.apache.org/dist/hbase/2.0.2/hbase-2.0.2-bin.tar.gz
Local
1scp "C:\Users\i\Downloads\Compressed\hbase-2.0.2-bin.tar.gz" root@ecs-2019211379-0001:/usr/local
传输到各个节点
Nodes:
scp /usr/local/hbase-2.0.2-bin.tar.gz root@ecs-2019211379-0002:/usr/local
scp /usr/local/hbase-2.0.2-bin.tar.gz root@ecs-2019211379-0003:/usr/local
scp /usr/local/hbase-2.0.2-bin.tar.gz root@ecs-2019211379-0004:/usr/local
解压
1cd /usr/local
2tar -zxvf hbase-2.0.2-bin.tar.gz
3ln -s hbase-2.0.2 hbase
1vim /etc/profile
设置环境变量
1export HBASE_HOME=/usr/local/hbase
2export PATH=$PATH:$HBASE_HOME/bin:$HBASE_HOME/sbin
1source /etc/profile
1cd $HBASE_HOME/conf
2vim hbase-env.sh
1export JAVA_HOME=/usr/local/jdk8u252-b09
2export HBASE_MANAGES_ZK=false
3export HBASE_LIBRARY_PATH=/usr/local/hadoop/lib/native
查看自己的 Java 路径:
1update-java-alternatives -l
2---
3java-1.8.0-openjdk-amd64 1081 /usr/lib/jvm/java-1.8.0-openjdk-amd64
则
1export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
2export HBASE_MANAGES_ZK=false
3export HBASE_LIBRARY_PATH=/usr/local/hadoop/lib/native
配置 hbase-site.xml
1vim hbase-site.xml
插入配置:
1<configuration>
2 <property>
3 <name>hbase.rootdir</name>
4 <value>hdfs://ecs-2019211379-0001:8020/HBase</value>
5 </property>
6 <property>
7 <name>hbase.tmp.dir</name>
8 <value>/usr/local/hbase/tmp</value>
9 </property>
10 <property>
11 <name>hbase.cluster.distributed</name>
12 <value>true</value>
13 </property>
14 <property>
15 <name>hbase.unsafe.stream.capability.enforce</name>
16 <value>false</value>
17 </property>
18 <property>
19 <name>hbase.zookeeper.quorum</name>
20 <value>ecs-2019211379-0002:2181,ecs-2019211379-0003:2181,ecs-2019211379-0004:2181</value>
21 </property>
22 <property>
23 <name>hbase.unsafe.stream.capability.enforce</name>
24 <value>false</value>
25 </property>
26</configuration>
Vim 通过
:set paste启用粘贴模式,避免粘贴错位。然后再set nopaste。
配置 regionservers
1vim regionservers
替换为
ecs-2019211379-0002
ecs-2019211379-0003
ecs-2019211379-0004
1ln -s /root/modules/hadoop-3.3.2/etc/hadoop/hdfs-site.xml /usr/local/hbase/conf/hdfs-site.xml
启动
在 node1 启动
1/usr/local/hbase/bin/start-hbase.sh
遇到的问题
-
ecs-2019211379-0002: regionserver running as process 3406. Stop it first. 解决方法:不用解决,因为你不应该在其它结点执行
start-hbase.sh。 -
PleaseHoldException: Master is initializing 先清理数据(慎重)
1/usr/local/zookeeper/bin/zkServer.sh stop 2rm /usr/local/zookeeper/tmp/version-2/* -rfd 3/usr/local/zookeeper/bin/zkServer.sh start 4/usr/local/zookeeper/bin/zkServer.sh status然后看日志:
1root@ecs-2019211379-0004:/usr/local/hbase/conf# tail ../logs/hbase-root-regionserver-ecs-2019211379-0004.log 2Caused by: org.apache.hbase.thirdparty.io.netty.channel.AbstractChannel$AnnotatedConnectException: connect(..) failed: Invalid argument: ecs-2019211379-0001/192.168.0.93:16000 3 at org.apache.hbase.thirdparty.io.netty.channel.unix.Errors.throwConnectException(Errors.java:107) 4 at org.apache.hbase.thirdparty.io.netty.channel.unix.Socket.connect(Socket.java:255) 5 at org.apache.hbase.thirdparty.io.netty.channel.epoll.AbstractEpollChannel.doConnect0(AbstractEpollChannel.java:758) 6 at org.apache.hbase.thirdparty.io.netty.channel.epoll.AbstractEpollChannel.doConnect(AbstractEpollChannel.java:743) 7 at org.apache.hbase.thirdparty.io.netty.channel.epoll.AbstractEpollChannel$AbstractEpollUnsafe.connect(AbstractEpollChannel.java:585) 8 ... 15 more 9Caused by: java.net.ConnectException: connect(..) failed: Invalid argument 10 ... 20 more 112022-04-20 16:05:14,228 WARN [regionserver/ecs-2019211379-0004:16020] regionserver.HRegionServer: reportForDuty failed; sleeping and then retrying. 122022-04-20 16:05:17,229 INFO [regionserver/ecs-2019211379-0004:16020] regionserver.HRegionServer: reportForDuty to master=ecs-2019211379-0001,16000,1650441887334 with port=16020, startcode=1650441888289 132022-04-20 16:05:17,231 WARN [regionserver/ecs-2019211379-0004:16020] regionserver.HRegionServer: error telling master we are up1root@ecs-2019211379-0001:~# netstat -nltp | grep 16000 2tcp6 0 0 192.168.0.93:16000 :::* LISTEN 4423/java查询资料可知,这个端口是 HBase Master 的默认端口。也就是说 ZooKeeper 里注册的 Master 地址是 ecs-2019211379-0001/192.168.0.93:16000.
1root@ecs-2019211379-0004:~# telnet ecs-2019211379-0001 16000telnet 正常。
1root@ecs-2019211379-0001:~# /usr/local/hbase/bin/stop-hbase.sh 2root@ecs-2019211379-0001:~# /usr/local/hbase/bin/start-hbase.sh无效
查看日志:
root@ecs-2019211379-0001:~# vi /usr/local/hbase/logs/hbase-root-master-ecs-2019211379-0001.log 2022-04-20 16:08:19,536 INFO [Thread-14] client.RpcRetryingCallerImpl: Call exception, tries=19, retries=46, started=209164 ms ago, cancelled=false, msg=Call to ecs-2019211379-0004/192.168.0.101:16020 failed on connection exception: org.apache.hbase.thirdparty.io.netty.channel.AbstractChannel$AnnotatedConnectException: syscall:getsockopt(..) failed: Connection refused: ecs-2019211379-0004/192.168.0.101:16020, details=row 'hbase:namespace' on table 'hbase:meta' at region=hbase:meta,,1.1588230740, hostname=ecs-2019211379-0004,16020,1650439274835, seqNum=-1 2022-04-20 16:08:19,629 WARN [master/ecs-2019211379-0001:16000] assignment.AssignmentManager: No servers available; cannot place 1 unassigned regions.也就是说主节点无法访问其它节点。测试一下:
1root@ecs-2019211379-0001:~# telnet ecs-2019211379-0004 16020 2Trying 192.168.0.101... 3telnet: Unable to connect to remote host: Connection refused果然如此。
一看,监听的是 tcp6 本地环回地址:
1root@ecs-2019211379-0004:~# netstat -nltp | grep 16020 2tcp6 0 0 127.0.1.1:16020 :::* LISTEN 5478/java最终解决方案:
vi /etc/hosts,注释如下行: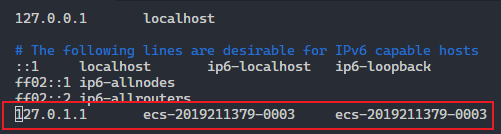
PS:华为云真是恶心,我不是都注释掉了吗,每次重启都要给我设置回来,醉了。
1root@ecs-2019211379-0001:~# /usr/local/hbase/bin/stop-hbase.sh 2root@ecs-2019211379-0001:~# /usr/local/hbase/bin/start-hbase.sh问题解决。
检查
正确状态 jps:
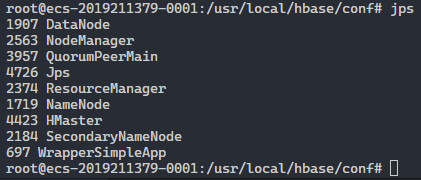
从节点:
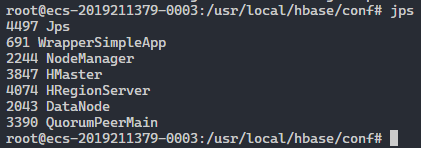
HBase 使用实践
基础概念
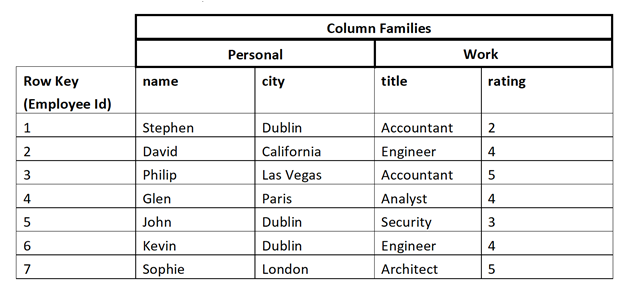
- 列族(Column Family)——每个列簇有多个列。看下面的图就明白了,
Personal和Work是两个列族。
常用命令
创建带有列族的表:
1create 'employee', {NAME => 'Personal', VERSIONS => 1}, {NAME => 'Work', VERSIONS => 1}
成功的话会显示:Created table employee
当然,也可以简单一点:
1create 'employee', 'Personal', 'Work'
由于已经创建过,会显示:ERROR: Table already exists: employee!
1hbase shell
创建表:
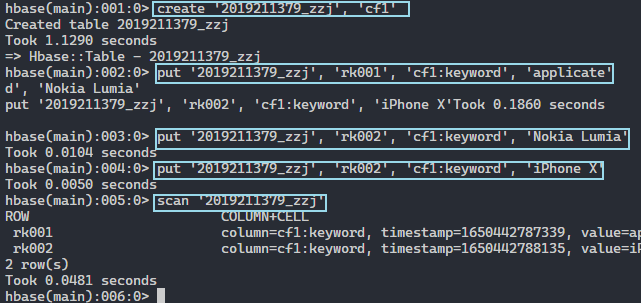
1create '2019211379_zzj', 'cf1'
插入数据:
1put '2019211379_zzj', 'rk001', 'cf1:keyword', 'applicate'
2put '2019211379_zzj', 'rk002', 'cf1:keyword', 'Nokia Lumia'
3put '2019211379_zzj', 'rk002', 'cf1:keyword', 'iPhone X'
扫描数据:
1scan '2019211379_zzj'
编程实践
代码如下:
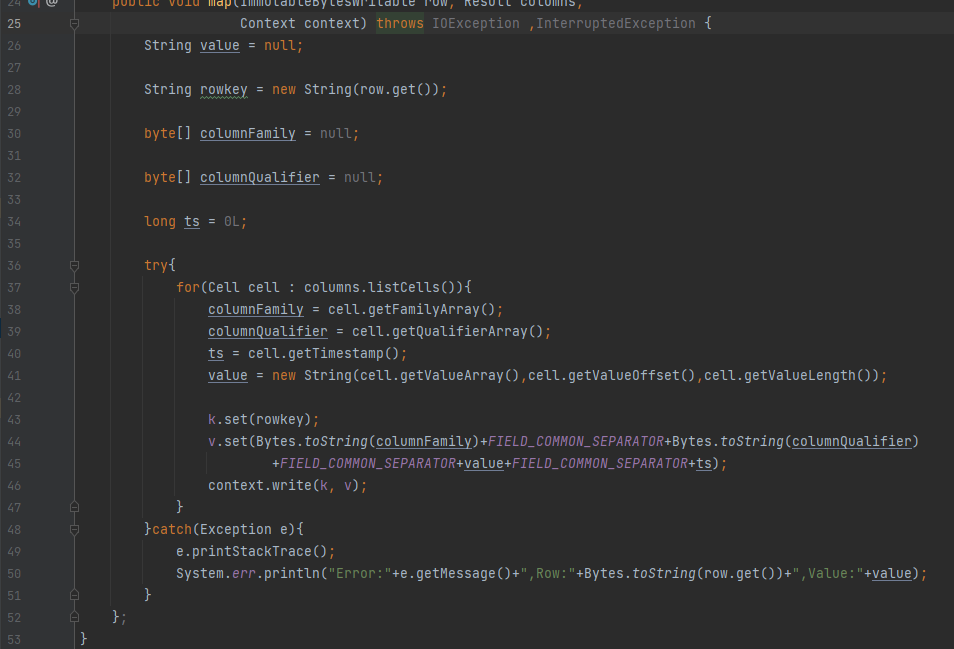
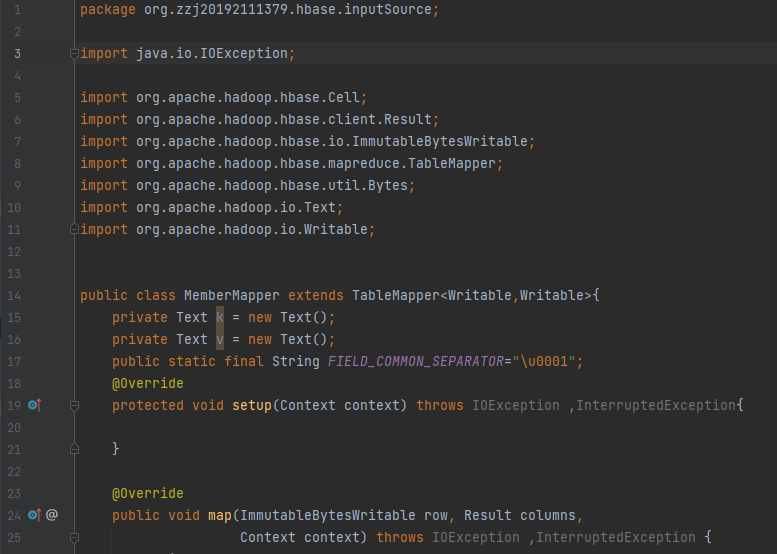
代码说明
-
我们创建了一个 Scan,然后调用 addColumn 用于限定查询的列族。
-
speculative.execution是试探执行,用于在某个 Node 执行太慢时,让其他 Node 执行备份。我们这里关闭了这个功能。 -
然后创建了一个 Job,名为
Member Test1,initTableMapperJob将表、Mapper 和 Job 相关联。 -
最后我们指定输出到
tmpIndexPath并等待执行完成。
打包之后,scp 到服务器。然后执行:
1hadoop jar MyHBase.jar org.zzj2019211379.hbase.inputSource.Main
等待任务完成:
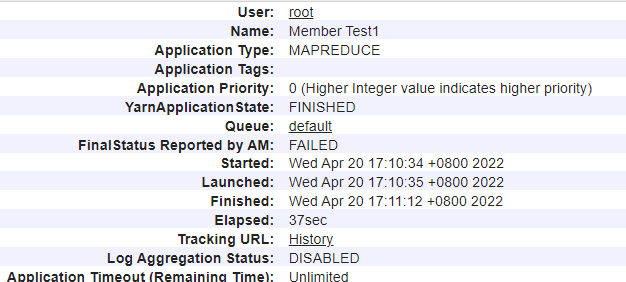
查看结果:
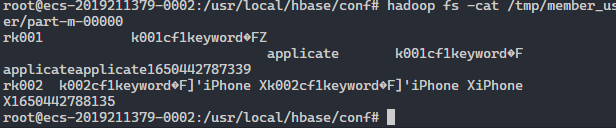
遇到的问题
-
Application is added to the scheduler and is not yet activated. Queue’s AM resource limit exceeded
Diagnostics: [Wed Apr 20 16:59:05 +0800 2022] Application is added to the scheduler and is not yet activated. Queue's AM resource limit exceeded. Details : AM Partition = <DEFAULT_PARTITION>; AM Resource Request = <memory:2048, vCores:1>; Queue Resource Limit for AM = <memory:4096, vCores:1>; User AM Resource Limit of the queue = <memory:4096, vCores:1>; Queue AM Resource Usage = <memory:4096, vCores:4>;分析:内存不足。
解决方法:
yarn-site.xml1<property> 2 <name>yarn.scheduler.capacity.maximum-am-resource-percent</name> 3 <value>0.5</value> 4</property>此处表示允许使用 50% 的内存。